- Acme: A Research Framework for Distributed Reinforcement Learning
- REVERB: A FRAMEWORK FOR EXPERIENCE REPLAY
Acme: A Research Framework for Distributed Reinforcement Learning
Acme is a library of reinforcement learning (RL) building blocks that strives to expose simple, efficient, and readable agents. These agents first and foremost serve both as reference implementations as well as providing strong baselines for algorithm performance. However, the baseline agents exposed by Acme should also provide enough flexibility and simplicity that they can be used as a starting block for novel research. Finally, the building blocks of Acme are designed in such a way that the agents can be written at multiple scales (e.g. single-stream vs. distributed agents).
摘自 https://github.com/deepmind/acme
Acme是Deepmind出品的用于快速构建强化学习算法原型的分布式强化学习框架
官网:https://deepmind.com/
文档(非常不完善):https://dm-acme.readthedocs.io/en/latest/
github地址:https://github.com/deepmind/acme
下面介绍其于arXiv中撰写的文章 https://arxiv.org/abs/2006.00979
Acme对actor和环境交互的抽象如下图:
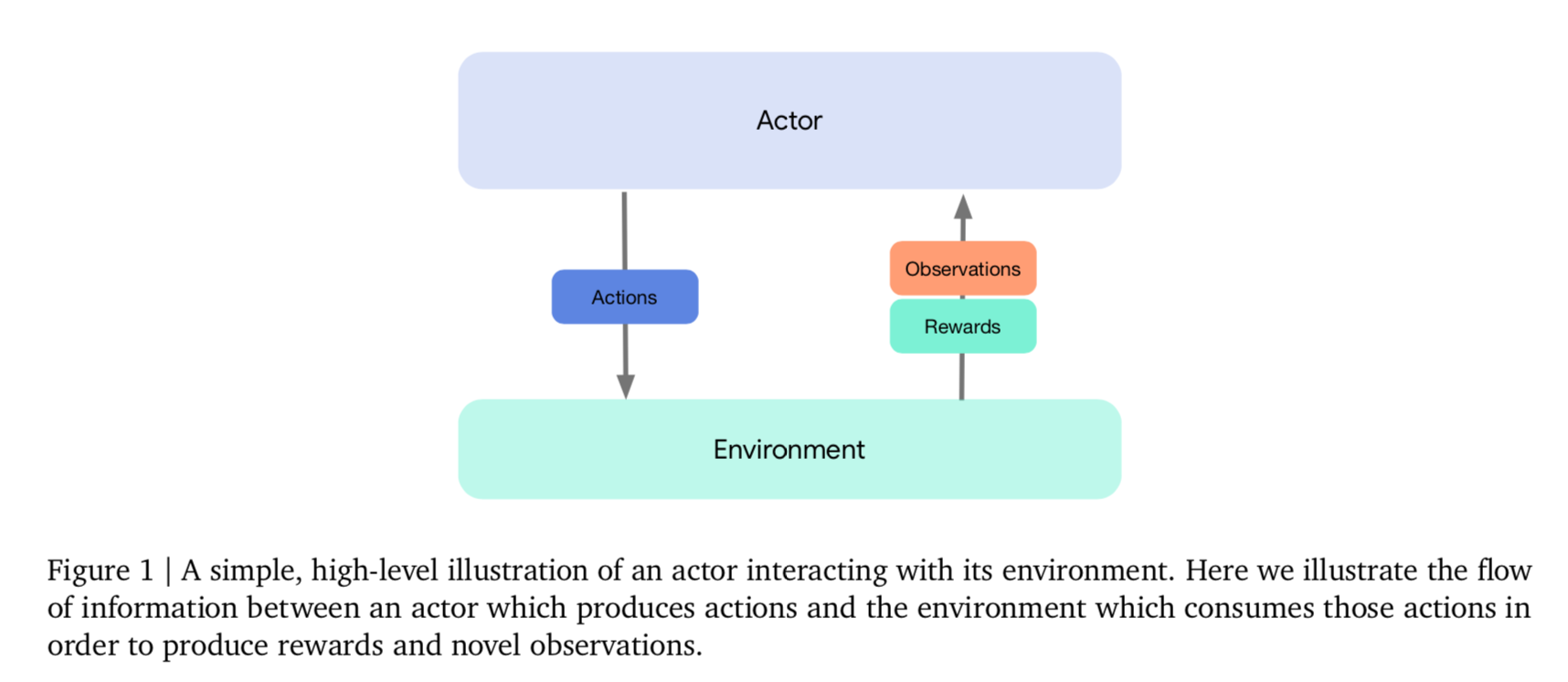
图中基本包含一个标准强化学习的配置,包含一个具有学习能力的agent——可以感知环境并和环境作出交互行为。agent主要由其策略π表征,将其经验历史例如Observations(O_0, O_1, O_2, O_3, ......, O_t)映射到一个行为a_t。当agent的行为作用在环境时,会产生一个激励信号R_t,以及一个新的观测O_t+1,然后往复循环这一过程。
下图为这一过程的具体图示及其伪代码
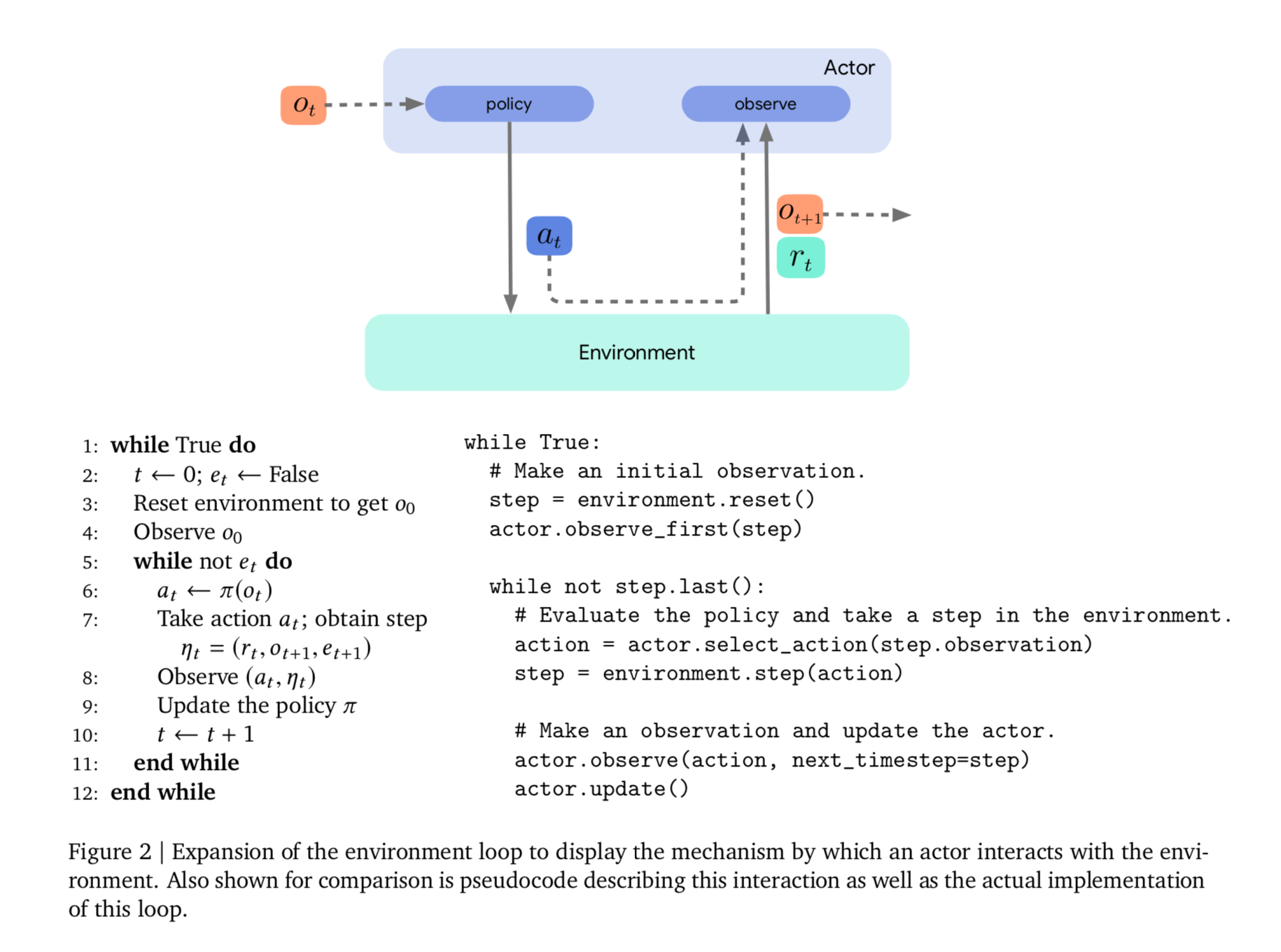
1. Environments, actors, and environment loops
- 强化学习的核心概念之一是agent与之交互的环境Environment。我们将假定一个环境,它保持自己的状态,并顺序地与actor交互,以便产生一个元组(r_t,o_t+1,e_t+1),其由奖励、新的观测和事件结束指示符组成。
- Acme中与环境交互最紧密的是actor,从上层看,actor使用环境产生的观察结果,并产生行为反过来作用在环境上。然后,在观察接下来的变化后,actor将更新它内部的状态,这通常取决于他的行动选择策略。
- actor和environment之间的交互是由environment loop调整的。Acme提供了一个通用loop,它满足我们的大多数需求,并提供了一个简单的entry point,用于与在Acme中实现的任何actor或agent进行交互。
下图为一个learning agent的例子:
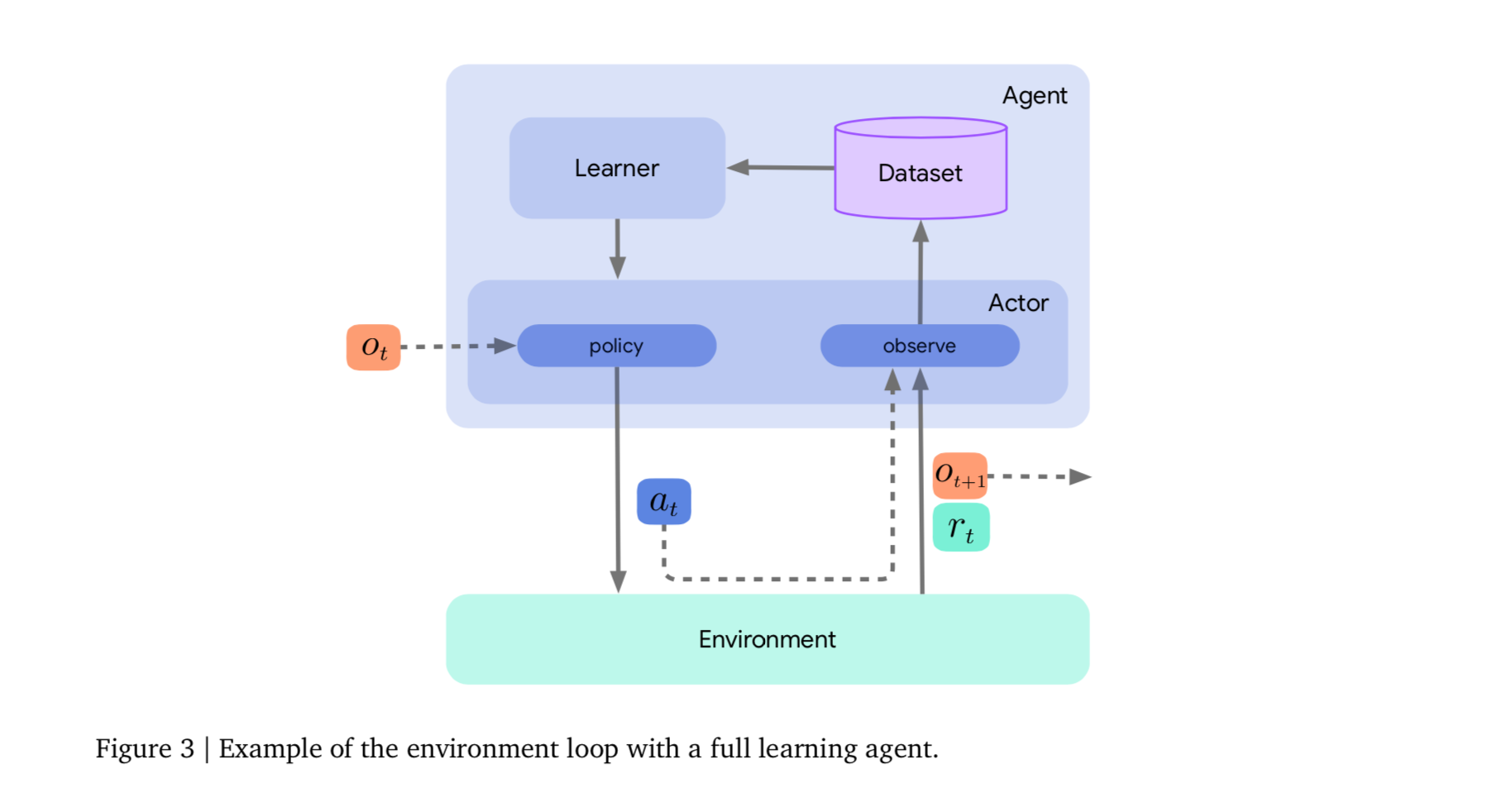
2. Learners and Agents
- 现在引入Learner组件,它消耗上述获得的数据,以生成更好的策略。Learner组件通常包含与任何特定RL算法相关的大量代码,并且在深度强化学习中,采用优化神经网络权重的形式,以最小化某些特定于算法的损失。下面将以一种特殊的actor,称为agent,表示包括了actor和learner的部分,以与非学习actor进行区别。
- 当一个agent的行为选择遵循它自己的acting组件,它的更新方法就是一个agent在它的learner组件中触发一定数量的学习步骤。相比之下,一般的actor更新方法只是简单地从一个变量源提取神经网络的权值。由于learner组件是一个有效变量源,actor组件可以直接查询learner的最新网络权重,这在分布式agent中十分有用。
- 在上图中,有一个新的environment loop,以显示刚才描述的learning agent的内部结构。特别的,actor从learner中获取权重,保持其行动选择是最新的。与此同时,learner将actor观察到的experience从dataset中提取出来,这是另一个重要的组成部分。
3. Datasets and Adders
- 在actor和learner组件之间拥有一个dataset组件是一个十分普遍的观点,它同时可用于on-policy和off-policy学习,可以根据对dataset的配置对experience replay(经验重放)进行优先级排序。从learner的角度看,数据被简单地提供为抽样的小批量流;可以将dataset配置为保留旧数据,并且/或可以对actor进行编程,为learner指定的策略添加干扰。Acme的Dataset已经对TensorFlow的Dataset对象进行了标准化,以提供对数据的有效缓冲和迭代,但这并不要求在learner实现的更新步骤中使用TensorFlow。数据集本身由一个低级数据存储系统支持,称为Reverb (Albin Cassirer, Gabriel barh - maron, Manuel Kroiss, Eugene Brevdo, 2020),该系统同时发布。Reverb可以粗略地描述为一种存储系统,它能够实现items的有效插入和路由,以及一种灵活的采样机制,它允许:先进先出、后进先出、均匀采样和加权采样方案。
- Acme提供了一个简单的公共接口,用于以Adder的形式插入底层存储系统。大多数的actor的observation被直接转发到Adder上,这些对象的存在是为了允许在插入数据集之前对observation data进行不同类型的预处理和聚合。例如,给定的agent实现可能依赖于采样转换、n步转换、序列(重叠或不重叠)或整个集合,所有这些在Acme中都有现有的Adder实现。
强化学习中on-policy 与off-policy有什么区别? - 知乎用户SIuYk2的回答 - 知乎
https://www.zhihu.com/question/57159315/answer/164323983
4. Distributed agents
- 到目前为止,我们主要使用一个简单的同步设置来描述actor或agent与其环境之间的交互。然而,一个常见的用例是从学习过程中异步生成数据,通常是通过与多个环境并行交互。在Acme中,我们通过将前面介绍的acting、learning和storage组件分解到不同的线程或进程中来实现这一点。这有两个好处:第一,环境交互可以与学习过程异步进行,即我们允许学习过程尽可能快地进行,而不管数据收集的速度如何。以这种方式构建agent的另一个好处是,通过并行使用更多的actor,可以加速数据生成过程。
一个分布式agent的例子可以看下图:
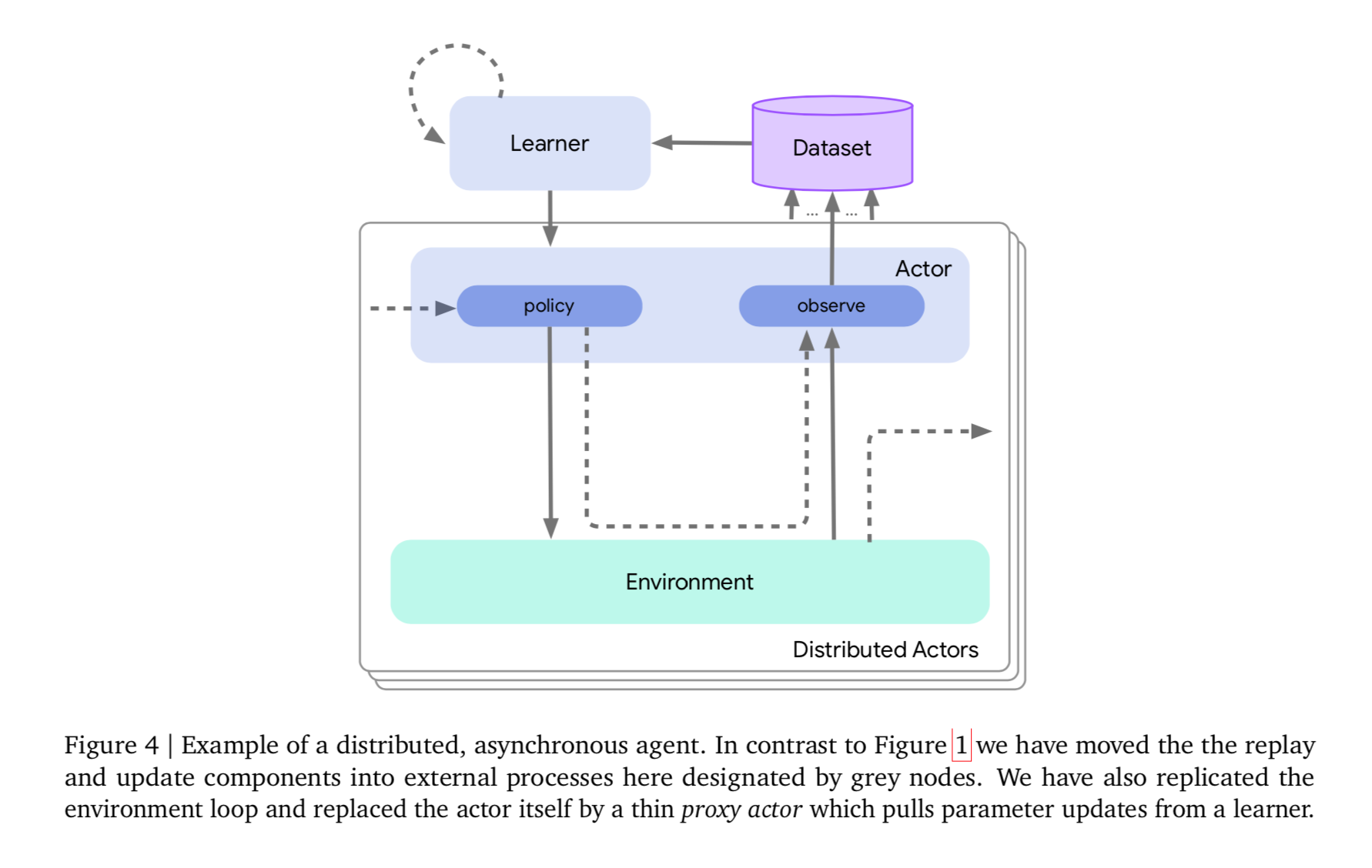
- 可以看到分布式agnet和前面的single-stream agent保持了很大结构上的相似性。但是前面的不同模块之间的链接仅用于指示函数调用关系,但在分布式agent中,每个模块在其自己的进程中启动,其中不同模块之间的链接用于说明远程过程调用(RPC)。在示例中,其包含了一个数据存储进程,一个learner进程,一个或多个actors,每一个都有独自的environment loop。为了简化这个构造,我们还经常在actor流程上使用一个附加的子模块: a variable client。这纯粹是为了让actor轮询learner来获取变量更新,并简化代码(如果learner需要推送给每个actor,这就更麻烦了)。
- 为了实现分布式agent,开发了Launchpad,用以支持该功能。上面介绍的agent本身由不同的子模块组成,例如,actor、learner和data storage system。以同样的方式,Launchpad可以被看作是在分布式配置中组合这些模块的机制。Launchpad提供了一种机制,可以将分布式程序创建为由节点和边组成的图。节点与上面描述的以类实例表示的模块完全对应,而边表示允许两个模块之间通信的客户机/服务器通道。一旦构建好这个图,就可以启动程序开始其底层的计算。Launchpad的主要创新在于它处理这些边的创造过程,从所有模块的角度看都没有区分本地和远程通信,例如一个actor从learner获取参数的过程看起来就像一个方法调用。
5. Reverb and rate limitation
- Experience Replay成功的应用于深度强化学习中,这允许agent重复使用过去的经验。在acme中,observation是通过actor的observe()方法添加到replay buffer中的,这个方法在每个时间步中都会调用,然后使用learner的update()方法从缓冲区中采样用于训练代理的批量转换。Reverb提供了配置replay buffer的选项,用户可以专注于agent行为的代码实现,而不必关注replay buffer的使用。
- 在同步学习循环中,您可以指定您的代理在每个学习步骤之间在环境中执行多少个步骤。行为和学习之间的比率不仅对样本效率(达到给定性能所需的环境步骤数量)有显著影响,而且对长期学习性能和稳定性也有显著影响。对于分布式学习设置也是如此,尽管这种设置使得保持固定的比率变得更加困难。事实上,如果分配代理是为了计算效率,那么当actor进程收集数据时,阻止学习过程显然是不可取的。另一方面,独立运行两个进程很容易导致更高的方差。这种差异通常是由于种子之间的计算基板(例如不同的硬件和网络连接)的差异,但精确地确定源是极具挑战性的。
- 在同步学习循环中,可以指定agent在每个learning步骤之间在环境中acting多少个步骤。acting和learning之间的比率不仅对采样效率有影响,对长期learning agent性能和稳定性也有显著影响。当actor进程收集数据时,阻塞 learning process显然是不可取的。在Acme中,通过使用Reverb的RateLimiter可以缓解这些尺度问题。通过采用速率限制,人们可以强制执行一个期望的相对学习速率,允许actor和learner进程保持在规定速率的某种限定容忍度之内不受阻碍地运行。在理想的设置下,两个进程都有足够的计算资源,以便速率限制器不阻塞地运行。然而,如果由于网络问题、资源不足或其他原因,其中一个进程开始落后于另一个进程,速率限制器将阻塞后者,而前者迎头赶上。虽然这可能会浪费计算资源,使后者处于空闲状态,但它只在必要时这样做,以确保learning和acting的相对速度保持在容忍范围内。
6. Offline Agents
上述为Acme Agent采用的结构的另一个好处是,将任何学习组件应用到离线设置中都很简单,脱机设置假设有一个固定的experience数据集,可以通过纯监督的方式学习。在Acme中,这就像将给定的learning模块应用到给定的experience数据集一样简单。由于纯粹的批处理配置和off-policy之间有大量重叠,许多off-policy agent在不允许与环境交互时工作得相当好。
文章中后续介绍了强化学习Agent的一些算法数学原型,这里不作赘述,可参考原文。实验部分是运行了一些RL算法实例,测试了Actor各个模块能正常运行,以及特定模块测试,比如Reverb的RateLimiter限制器。
下面对Acme中使用到的经验重放框架Reverb作介绍
REVERB: A FRAMEWORK FOR EXPERIENCE REPLAY
文章地址:https://arxiv.org/abs/2102.04736
Reverb:https://github.com/deepmind/reverb
RL中的Experience扮演了一个非常关键的角色,如何有效利用数据是该领域的关键问题。随着RL Agent近年来的发展,其承担了更多更复杂的挑战,比如在Atari,星际争霸,Dota游戏上的发展,这同时催生了大尺度、高吞吐量的数据。为了加速数据收集过程,许多RL试验将agent分成两个部分,数据发生器(actors)以及数据的消费者(learners),这两部分可以并行地运行。尽管如此,数据仍然必须进行存储,还要在消费者和发生器之间传输。高效地传输和存储数据是一个不小的工程难题。
为了解决这一问题,Deepmind提出了Reverb:一个高效,可拓展的,并且易于使用的用于传输存储experience的系统。Reverb十分适用于Experience Replay(ER),或者Prioritized Experience Replay (PER),这是很多off-policy算法的关键组件,例如DQN,DDPG,Soft Actor-Critic算法。Reverb同样适用于FIFO、LIFO或基于堆的队列,允许on-policy的方法例如Proximal Policy Optimization。
Reverb的另一个特点是高效,适用于具有大量actor和learner同时运行的大型RL Agent。这允许研究人员研究不同规模的问题,而不必更改基本组件。
Reverb提供了一个易于使用的机制,以控制采样与插入数据元素的比率。这个比率通常用于设置每个数据元素进行梯度更新的次数,这会显著影响RL算法的性能。在同步配置中,这个实现很容易,但在分布式系统中并发运行Actors时,就变得困难。使用Reverb可以让用户在RL测试中控制数据收集和训练的相对速率,而不比考虑规模(scale)。
结构设计
Reverb的核心是一个数据仓库,其向外部的客户端暴露gRPC API,客户使用API写入原生的tensor data。数据作为Chunk的一部分写入到ChunkStore, Chunk可以被Items引用,每个Item属于一个Table。Table封装了Items,并使用RateLimiter和两个选择器(一个采样器和一个移除器)控制样本和插入请求。这些组件是独立配置的,并且可以混合配对,以提供高灵活性和支持不同行为。
data构成chunk如下图所示:
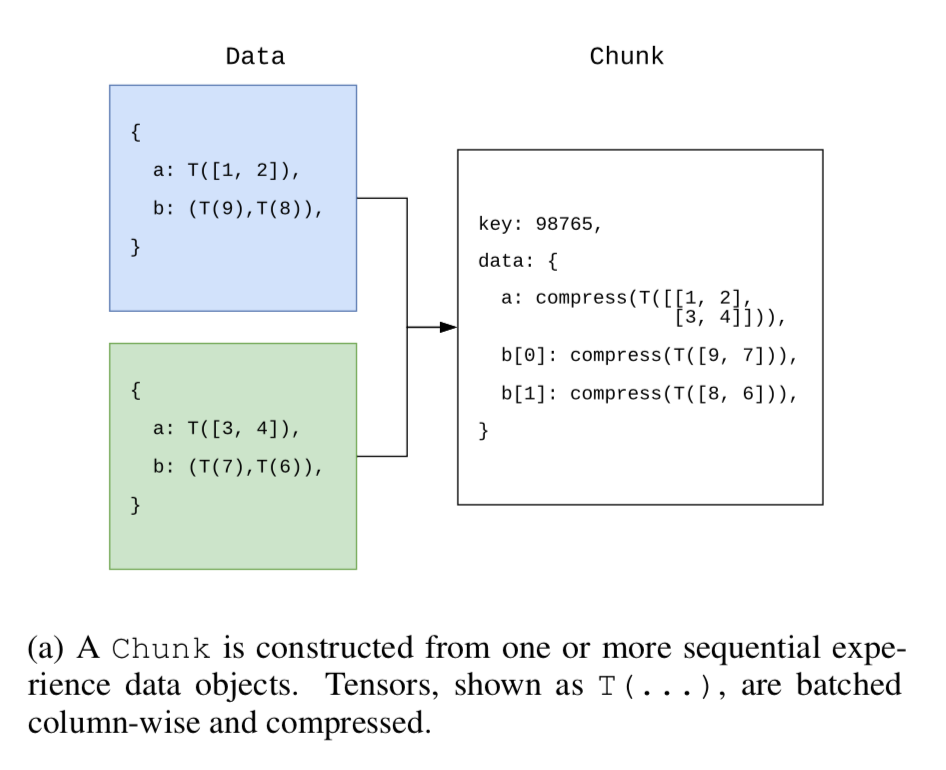
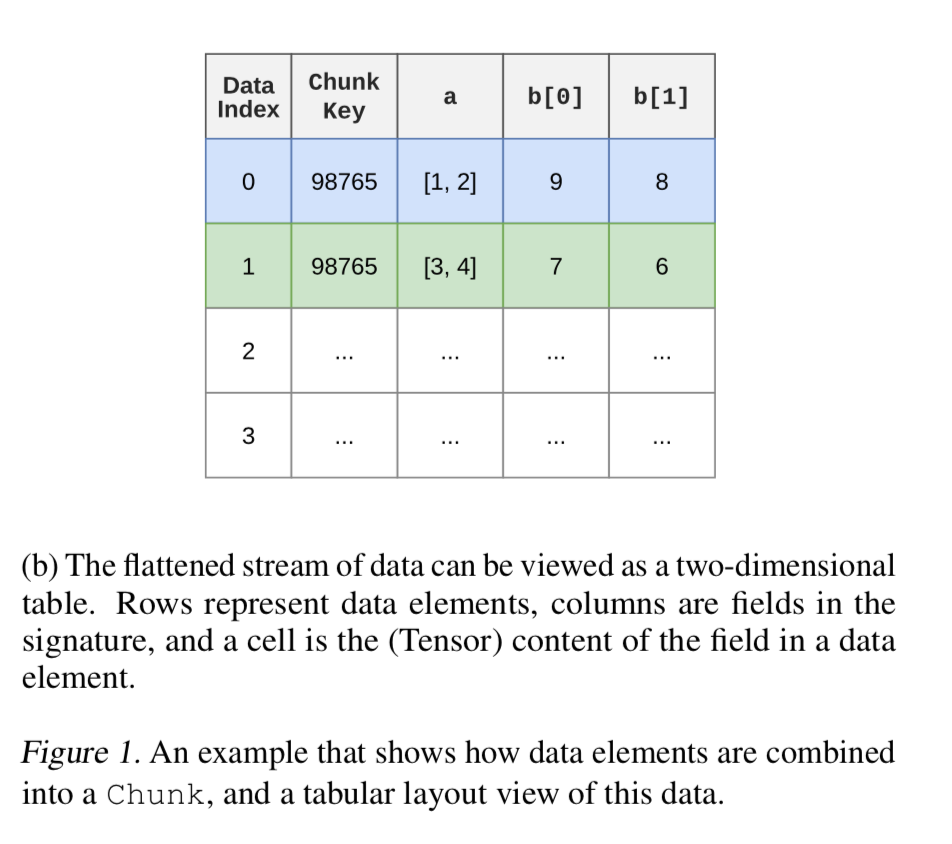
Chunking and the ChunkStore
RL环境产生的数据通常在各个step保持相当高的相似性,比如在Atari生成的两个连续帧的像素,大部分像素在两帧中都是相同的,Reverb利用这种相似性,将顺序的数据元素放置到chunk中,并应用column wise concatenation(列优先连接)和压缩。在上图1 b)中,每一个cell都代表具有特定结构的一个tensor。
Chunk减少了内存占用和网络使用:其一,顺序数据元素被组织成chunk并且被压缩;其二,Chunk对原生数据抽象允许多个Item(Item可以属于不同TABLE)去引用相同的底层数据,而Item不必维护各自data的副本。
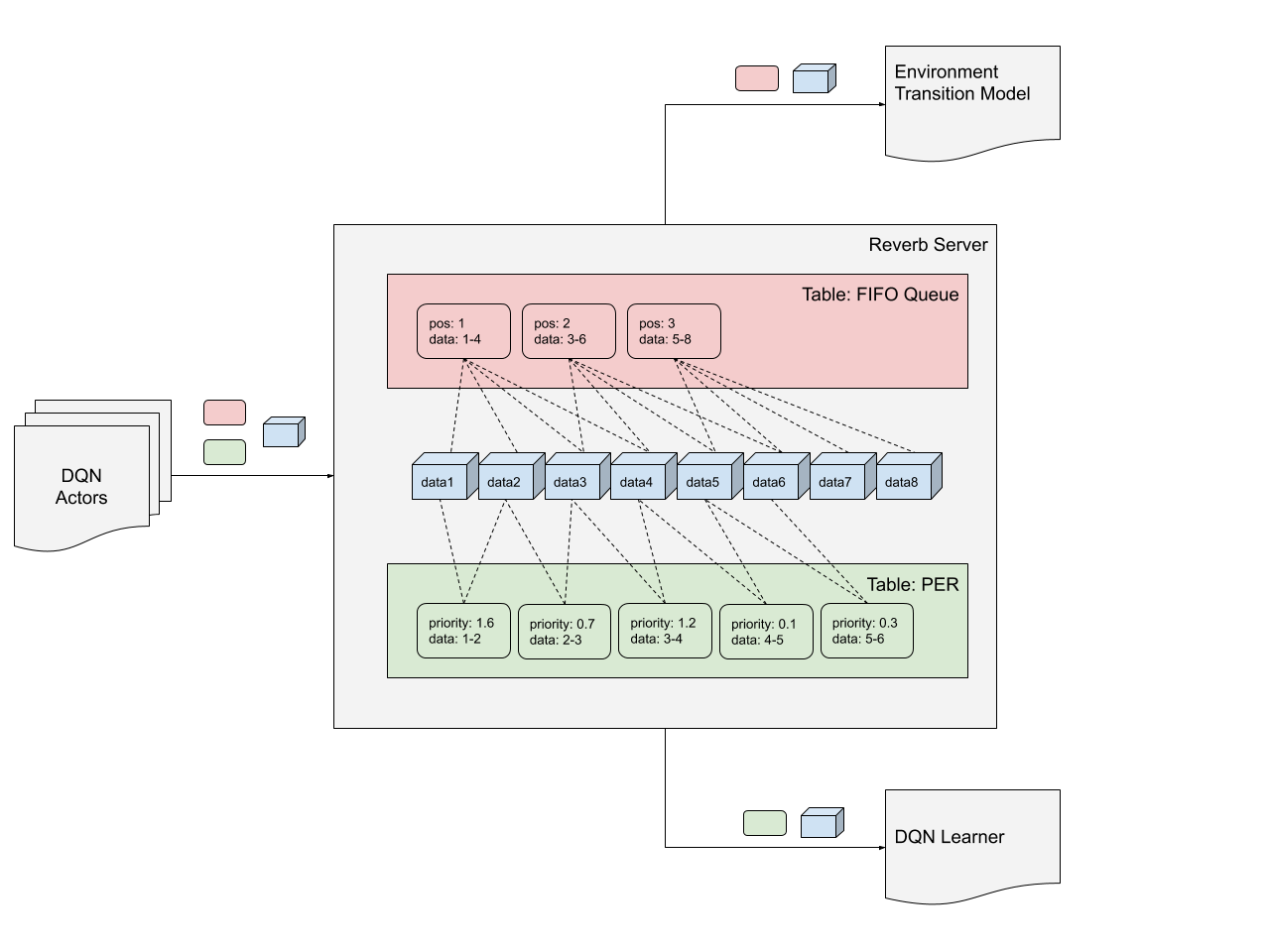
如下图:
下图是高级别的模块抽象:
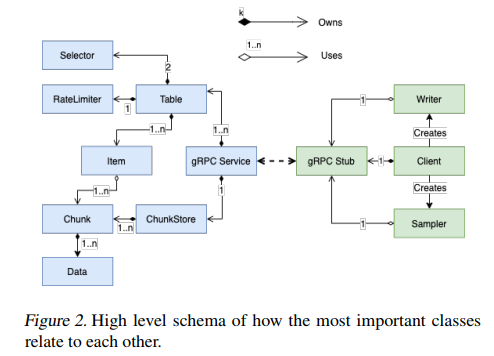
图中Chunk由ChunkStore持有,ChunkStore使用引用计数来跟踪Items对Chunk引用的数量。当引用计数归零,清空Chunk内存。Items通过Chunk实现引用和获取数据,ChunkStore将数据存储在内存。
Tables and Items
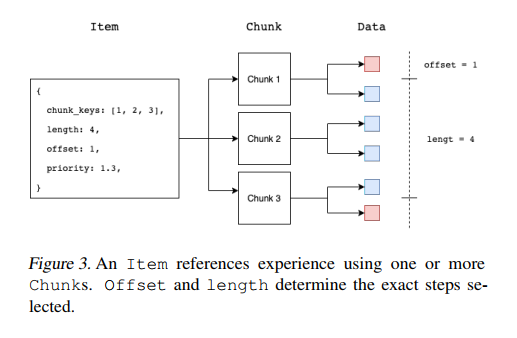
Reverb由一个或多个Table组成,Table包含Items,定义了采样和移除选择器,Item的最大容量,RateLimiter。
Item包含 1)unique key 2) 优先级,可用于采样或移除,可更新这个值 3)对一系列Chunks的引用 4)当前Item被采样的次数
Selectors
选择器用于从Table中选择Item,一个Table的选择器有两种,一个Sampler用于给Client选择Item,一个Remover用于当Table满了时移除Item。
Selectors支持5种策略:FIFO,LIFO,Uniform(均等可能选取),Max/Min Heap(根据priority选取),Prioritized(取Item权重占所有Item权重和的频数作为概率选取,实现了Prioritized Experience Replay 算法)
Rate Limiting
RateLimiter控制Item在Table中插入和采样的过程。RateLimiter监视Table的两个方面:1)Table中Item的数量,2)定义为SPI的 SPI=num_sampled_items/num_inserted_items
RateLimiter定义了
- 在开始抽样之前,Table必须包含的最小Item数量
- 目标SPIratio
- SPI ratio上下界
下图描述了一个阻塞插入数据的过程
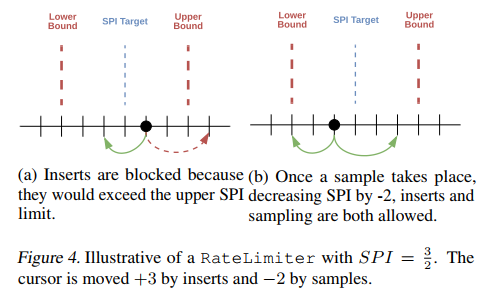
Reverb提供了多种限制器:SampleToInsertRatio、MinSize、Queue
Sharding
Reverb可以通过添加服务器进行水平拓展,当系统扩展到多服务器配置时,每个Reverb服务器不感知其他服务器,并且数据不会在服务器之间复制或同步。同样checkpointing是各自独立管理的,多服务器配置对数据容错并不比单独的服务器强或弱。
客户端操作以轮询的方式分布在服务器上,在采样时,每个客户端管理服务器连接池,采样请求并行的发送给多个服务器,收到的结果被合并为Item的单一流。这样减轻了长尾延时的影响,并且对单个服务器故障具有一定容错。
Checkpointing
ChunkSotre和Tables的状态和内容都可以序列化然后存储到磁盘中。可以通过周期性地checkpoint减少服务器failure时的数据损失。在服务器启动的时候可以从磁盘读取checkpoint。在进行checkpointing期间,服务器会阻塞所有的插入,采样,更新,删除请求。
Reverb客户端
Reverb将gRPC客户端包装起来,提供了更高级别的API来写入、修改、读取数据。
一个Sampler管理一个长期维护的gRPC流pool,每个流可以从单个Table中获取样本。一个Writer用来流出串行数据到服务器,并且将Item插入一个或多个Table中。单个gRPC流在Writer对象的生命周期中使用。使用append添加数据,使用create_item创建Item,调用append时候将数据推送到本地缓冲区,当缓冲区满,构造一个Chunk,然后Chunk通过打开的gRPC流传输给server。类似地,使用create_item创建的Item会被推送到本地缓冲区,直到它引用的所有块都被传输到服务器。
使用tf.data API进行高效采样
Reverb利用的tf.data框架提供流水线高吞吐的数据采样来训练模块。Reverb实现了一个快速的基于C++机制的用以读取和后处理数据的模块——ReverbDataset。ReverbDataset创建的Iterator每一个都包装了采样器Sampler,每个Sampler相应地维护一个可配置的长期stream。当一个流被使用,dataset能够以准确的顺序从Reverb服务器获取数据。
案例
- Overlapping trajectories

- Multiple priority tables
