Launchpad文章地址:https://arxiv.org/abs/2106.04516
开源项目:https://github.com/deepmind/launchpad
本文介绍Launchpad,它是一个编程模型,其简化了定义和启动分布式系统的过程,同时它专门为机器学习受众量身定制。因机器学习实践者通常不精通分布式系统的设计,Launchpad可以为非领域人员构建分布式机器学习的过程提供支持。
Introduction
现代数值框架:Tensorflow、Pytorch、JAX对机器学习做出了重大贡献,他们成功的关键因素是他们定义了给定数值计算的算子图(a graph of the operations)。另一方面,由于数据和模型尺寸越来越大,使用多设备分布式计算变得越来越频繁,但对编程人员负担较大。许多机器学习领域人员不熟悉分布式系统和通信引入的复杂性。这在强化学习中尤甚,在数据生成过程中就涉及具有复杂计算需求的异构组件,设备之间具有复杂的通信需求。
程序员当然可以使用更底层的分布式通信协议来搭建分布式机器学习算法,例如MPI,RPC,包括一些实现如gRPC,ZeroMQ。然后使用这些协议来实现分布式机器学习算法,使用合适的通信策略进行连接,这还具有更好的灵活性。但是,这其中的通信拓扑需要在每个分布式算法的服务中自行定义。
为了解决这些问题,Deepmind提出Launchpad,它是一个编程模型,可以简化定义和启动分布式计算实例的过程。该模型的基本概念是一个Launchpad Program,它将计算表示为服务节点的有向图,图中的边表示通过RPC可以进行节点之间的通信。Launchpad可以将Program定义与用于启动分布式程序的机制分开,这允许使用不同的Launcher以实现在不同的平台上(云提供商、托管集群等)执行相同的分布式系统。在启动时,Program数据结构被转换为一组服务,实现为一台或多台机器上的线程或进程。同时为定义的服务设置通信通道(gRPC通道)。
关于implicit/explicit communication https://www.streetdirectory.com/etoday/-ucwjff.html
related work
Ray同样提供了一个编程接口,将task和process边界解耦。Ray能够将大量Python任务调度到分布式进程上,此外,它还提供容错和精确的恢复机制。然而,精确恢复的开销对于机器学习应用程序来说通常是不必要的。而且容错还带来了底层系统复杂性的增加,使拓展和debug系统变得困难。
其他相关工作通常是限制在目标领域的解决方案,例如RLlib,Rlgraph,Caffe和Keras的监督学习。他们不提供分布式计算的通用接口,但他们构建在通用框架上。例如RLlib构建在Ray上,RLgraph和keras构建在pytorch或TensorFlow上。
Programming model
Launchpad是一种编程模型,它将分布式系统表示为描述系统拓扑结构的图数据结构。图中的每个节点node代表程序中的一个服务,即节点代表我们感兴趣运行的基本计算单元。节点(node)本身是数据结构,它定义了每个服务将要运行的计算。目前可以将节点类型(node types)视为实际计算的factory methods。当将节点添加到Launchpad graph时,将构造一个句柄(handle),该句柄充当对该节点的引用,并最终表示尚未构造的服务的client。程序图中的有向边表示两个服务之间的通信,当与一个节点关联的句柄在构造时交给另一个节点,就会创建这个有向边。注意这条边是从接收节点(接收handle的节点)发出的,表示接收节点将是发起通信的节点。这使得Launchpad可以简单地通过传递节点句柄来定义跨服务通信。
下图为一个简单的Launchpad程序及其相关图的示例:
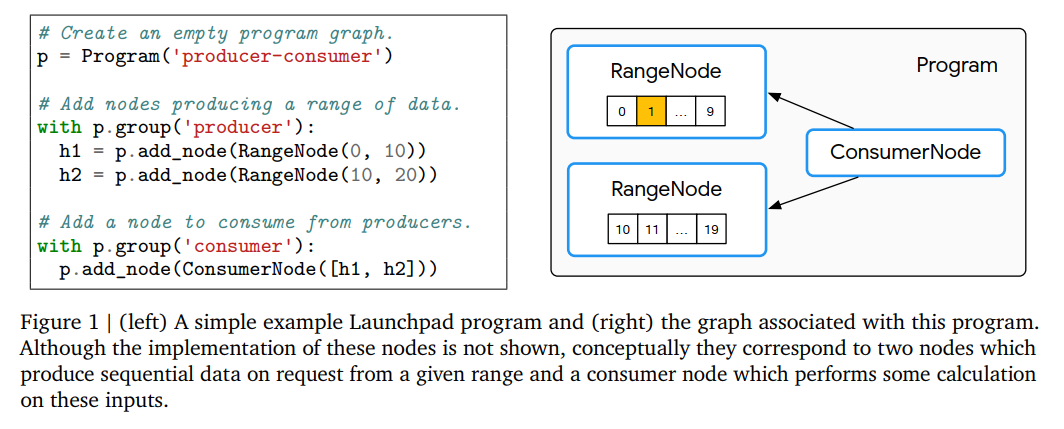
可以看到节点实例是类型化的,其中将执行的计算的确切形式取决于所使用的服务类型。节点也可以被分组成不相连的集合,形成所说的资源组。资源组允许程序在启动时设置特定平台的资源约束(例如分配RAM的数量或使用加速器的数量)。这些资源约束将应用于组集合中的每个节点。根据规范,每个节点只能分配给一个资源组,所有未分配的节点将被放置到一个默认资源组中。
Program数据结构最终负责描述整个分布式系统及其布局,但是当启动和执行系统时,程序将委派给每个单独的节点(本身是节点或服务类型的实例),来运行服务的计算。将这些单独的计算单元称为可执行程序(executables),服务本身可能由多个可执行程序组成。将节点的声明与实现解耦的好处是:提高了Launchpad生成系统的灵活性。节点的实现(可执行文件)可以是一个流程,一组流程,或只是简单引用现有服务。最后,Launchpad提供了特定于平台的启动器(launchers),这些启动器负责处理程序,以便创建和编译所有的worker对象,分配资源和约束,并最终将可执行程序发送到平台并执行它们。
Program Life cycle
Launchpad程序的生命周期大致可以分为三个阶段:Setup(构建)、Launch(启动/发射)和Execution(执行)。Setup阶段涉及Program数据结构的构造。在Launch阶段,这个数据结构被处理,以便分配资源、地址等,同时通过对将要运行的可执行文件执行任何必要的设置来启动指定的服务。最后,执行阶段开始运行服务,包括为服务之间的通信创建任何需要的客户端。从Launchpad的角度来看,执行阶段是最后一个阶段,在这之后,所有的控制都被移交给了各个可执行文件。
Setup
在Setup过程中,用户首先构造一个Program对象,该对象对应于一个空图。然后可以使用add_node成员函数向这个图添加节点。该方法接受一个Node实例,将其添加到内部图形结构中,并返回一个Handle,该Handle作为对该节点的引用。
在Setup阶段,用户还可以创建资源组并将节点分配给这些组。这是由Program.group方法创建的上下文实现的,以便将在此上下文中添加的任何节点分配给组。这种分组对于将公共资源定义应用到共享同构资源需求的一组节点很有用,例如,强化学习中的一组数据生成节点可能对每个模拟器共享相同的需求。
最后,虽然Setup阶段主要是描述程序的结构,但也需要进行一些有限的内部工作来支持后续阶段。特别地,为了允许不同服务在执行过程中进行通信,与给定节点关联的Handle对象需要一个地址(例如IP地址),该地址指向每个节点所代表的服务。然而,在启动阶段之前,节点的可执行文件并不会被创建,也不会分配相关的地址。直到可执行文件创建、分配到特定平台,地址才能确定。因此Node实例在Setup阶段必须创建地址占位符并将其分配给关联的句柄。这些占位符将在Launch阶段填充。
Launch
当将Program实例传递给特定于平台的启动器(launcher)时,Launch阶段就开始了。资源组到特定平台资源需求的映射也会一并传递,在创建可执行文件时,启动器对生成的可执行文件加以约束。
一个使用资源约束的例子:

启动器收到程序后,首先连接相应的分布式平台进行资源发现和供应。然后,启动器检查程序中引用的句柄,并将特定于平台的物理地址分配给相关的地址占位符。因为句柄可能分散在集群的不同地方,启动器会构造一个地址表来保存这个映射。
接下来,启动器遍历Program中的所有节点,并在每个节点上调用to_executables方法来创建后备可执行文件。由于所有地址在此时解析完成,如果节点接收到句柄,其对应的可执行文件将能够正确地使用解析的地址建立相关服务的联系。在必要的编译以后,生成的可执行文件将被发送到相应的分布式平台执行。
Execution
虽然程序是以集中的方式定义和启动的,但一般来说,程序的执行是完全分散和异步的。目标平台中的单个主机将在接收到可执行文件后开始执行它们。服务将被设置并绑定到启动阶段确定的地址,这样它们就可以相互联系和交互。
每个可执行文件进入它的run方法,该方法负责建立与前一阶段生成的地址(通过handle定义)相关联的任何通信客户端。然后可执行文件可以继续设置并运行它的服务,此时所有的计算都由给定的服务类型进行。
如果存在多个需要通信的主机,单个平台上的gRPC客户端会有多个吗?
Service Type
Launchpad暴露的计算构建块由不同的服务类型表示,其中每种服务类型都由特定于该类型的Node和Handle类表示。Node类是给定服务类型的面向用户的接口,用于配置特定的服务。虽然Handle实例也向用户公开,并在节点之间传递它们以用于指定通信通道,但它们的主要用途是用于创建实际客户端对象的deference方法。
节点之间的交流基于对Handle对象的解引用返回的客户端来进行,在许多情况下,客户端被公开为一个专门(arbitrary)的Python对象,其成员函数对应于对另一个服务的远程过程调用(RPC)。
Python Nodes
使用Python对象来表示每个服务。从计算的角度讲,使用Python不会对速度或拓展性造成阻碍。大部分机器学习应用,计算密集型应用都会使用低级别计算框架,如TensorFlow,PyTorch,JAX。
Launchpad通过引入PyNode和CourierNode类来对外暴露这种形式的服务。这两个类都以Python类和构造函数的参数作为输入,以便这些节点的实例充当底层类的延迟构造函数。另外,作为handle提供给其他节点的任何输入参数都将被特别处理,以便在执行节点时创建通信客户端。PyNode和CourierNode之间的区别:PyNode类型不返回Handle,也就不能接收消息,这为了减少开销而存在。而CourierNode类型将会公开暴露Handle引用。
被CourierNode实例创建的Handle最终将暴露为通用RPC对象,这样,对于一个使用Handle的人来说,对远程通信是不可见的,使用Handle就好像在使用原生的Python对象。这个服务类型的用法如下图(下图为Figure 1的完整实现):

需要注意的是,CourierNode并没有获得构造的Python对象。
与节点一起出现的是相应的句柄和可执行实现。在Launch阶段,构造的Python类在传递给节点实例被延迟,在这种情况下,CourierNode序列化类和任何给定的参数,然后在Launch时通过网络传递并反序列化。由于节点的参数可以包含句柄实例,因此在反序列化期间,worker还将dereference包含的任何句柄实例,然后再使用它们构造给定的类。然后worker启动一个RPC服务器,该服务器将从类中暴露所有的公共方法,如果存在run方法,则保存该方法。如果run方法存在,将执行它,否则将等待RPC调用。相应的CourierNode的CourierHandle也是这样实现的,在它的dereference方法中,构造的RPC对象将暴露每一个相关联类的方法。
代理模式
Others
Caching
配置Caching Node以缓解计算节点之间频繁的通信负担,下图是一个parameter server模型中配置Cache的例子:

Colocation
ColocationNode可以wrap一个node的集合,提供更细粒度的对单机器上不同Node的控制。
Data services
ReverbNode可以提供基于Reverb的数据访问服务,以供构建机器学习领域的应用使用。
Examples
Parameter Server
参考上面Caching的图片中的代码
MapReduce

Reinforcement Learning
