文献:Crail: A High-Performance I/O Architecture for Distributed Data Processing
收录于USENIX ATC 2019
官网 https://crail.incubator.apache.org/
文档 https://incubator-crail.readthedocs.io/en/latest/
背景介绍
高速网络和存储设备发展很快,但其优势并没有被现代分布式数据处理框架发挥出来。通常硬件集成在调用栈中的位置过低,硬件的性能很容易被高层次的软件开销掩盖。Crail应运而生,为了利用高性能网络和存储硬件,重新设计了一套用户级I/O架构,用于Apache数据处理系统。
传统的操作系统抽象不适应现代网络和存储硬件的改进,比如用于网络的套接字和用于存储的块设备,其不足以使应用程序获得丰富的语义以及进行高速I/O。同时,出现了新的接口协议,例如RDMA和NVMe,这些接口支持用户级硬件访问和异步I/O。
与此同时,大规模数据处理系统要求性能越来越高,新的I/O技术为大数据处理系统提供了进一步减小延迟的机会。尤其是在关键路径上的I/O操作,比如data shuffling或者作业、任务之间的数据交换、数据共享,将会受益于更快的I/O。尽管超级计算机利用高速I/O硬件的技术已经存在,最近也有一些学术研究,例如A plugin-based approach to exploit rdma benefits for apache and enterprise hdfs;High performance design for hdfs with byte-addressability of nvm and rdma;In-memory i/o and replication for hdfs with memcached: Early experiences。但这些应用都是为了特定的工作负载而设计的,在通用数据处理框架中,获得上述优势还存在一些挑战:
- Deep Layering: 硬件集成在stack中层次太低,其性能优势被上层软件开销掩盖。在现代的流行框架中,例如Spark、HDFS、Flink中,其heavy layering的系统层次劣势被放大了。数据需要在操作系统、JVM和框架的特定I/O子系统间穿越,导致不必要的data copy、context switch、cache pollution等。
- Data locality: 因为高性能网络和硬件的关系,现代分布式数据处理系统中I/O和计算的作用方式可以重新设计。低延迟的远程数据访问可以降低系统对数据局部性的依赖关系,从而能够从计算资源的角度思考,而不是必须从存储的角度思考。
- Legacy interfaces: 存储硬件种类(disk、flash、memory)越来越多,我们急切的需要有效使用各类存储资源。同时一些新技术(例如PCM)允许以byte粒度访问,这是还使用块设备接口访问存储就不太合适。同时,gpu和fpga拓展了传统的计算层,将这类加速器存储空间集成到现有分布式存储层次结构中也需要新的接口。将多种不同的硬件技术集成到现有数据处理系统中,也是一个新的挑战。
Crail I/O
Crail重新为高性能存储和网络硬件设计了一套用户级I/O架构,并为上述问题提供了综合性的解决方案。Crail的目标:
- Bare-metal performance: 使分布式系统的I/O操作能够充分利用现代网络和存储硬件
- Practical: 与现有的数据处理系统(Spark、Flink)充分融合,易于使用
- Extensible:未来的硬件技术易于以模块化的方式集成到当前架构中
- Storage tiering:提供基于高性能集群的新数据位置的高效存储分层。
- Disaggregation:为resource disaggregation提供显式支持。
概述
Crail I/O架构的主干是Crail store,这是一个高性能的多层数据存储,用于分析工作负载中的临时数据。
Crail模块(Crail module)负责实现各种高级I/O操作,是为各种数据框架定制的。例如Crail Spark实现Spark操作(Shuffle,broadcast),Crail HDFS提供标准HDFS接口,可以直接被应用调用,而无需修编译原先的应用程序或数据处理框架。Crail模块是Crail store顶部轻量级的层次。因此,这些模块在用户级I/O、性能和存储分层方面继承了Crail的全部优点。由于模块十分轻量级,为特定的数据处理框架或特定的I/O操作实现新模块只需要适度的工作量。
Crail Store
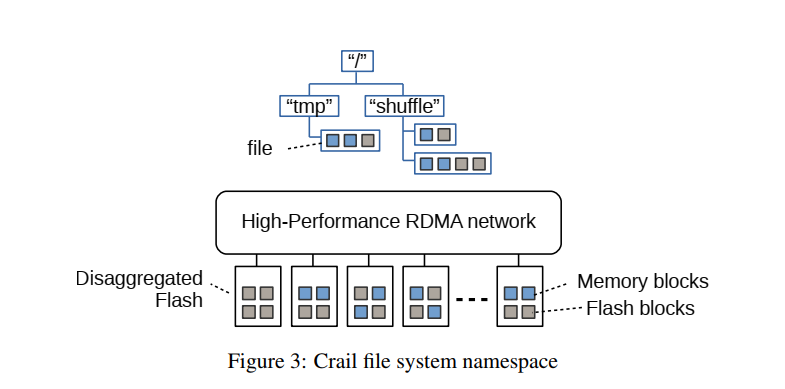
Crail在RDMA互联的存储资源(例如DRAM、flash)集群之上实现了文件系统命名空间。如上图,存储资源可以在计算节点,也可以分散在数据中心,也可以二者混合。总的Crail空间中的文件由分散在集群中的存储资源的blocks组成。存储层由存储介质和通过网络访问数据使用的网络协议定义,目前Crail实现了3类存储层:
- DRAM:DRAM层中,使用单边RDMA读写访问远端DRAM。在所有层中提供最低的时延和高通量。
- Shared Volume:共享卷层支持通过block存储协议(SCSI、RDMA、ISCSI等)的闪存访问。这一层利于整合分散的flash资源。
NVMeF:NVMeF存储层导出通过RDMA结构访问的NVMe flash。该存储层提供了对直接连接和分散的flash的超低延迟访问。
Crail提供了一个可扩展的存储接口,可以透明地插入新的存储层,而不需要更改文件系统核心。除了支持传统的存储层,Crail还在致力于将加速器内存集成到Crail存储层次结构中。例如,这将允许从集群的任何地方通过Crail访问GPU memory。
Crail Store接口
Crail提供了一个层次化文件系统API,其中包含创建、删除、读取和写入文件和目录的函数。除了这些标准操作之外,Crail API的大部分都是为了给更高级别的Crail模块赋予正确的语义,以最佳地利用网络和存储硬件来进行数据处理操作(例如,shuffle, broadcast等)。下面是几个具体的例子:
- Asynchronous I/O:Crail中的所有文件读写api都是完全异步的,这有利于数据处理过程中计算和I/O的交错执行。而且,异步api与RDMA或NVMeF中的异步硬件接口完全匹配,因此可以允许非常高效的实现。
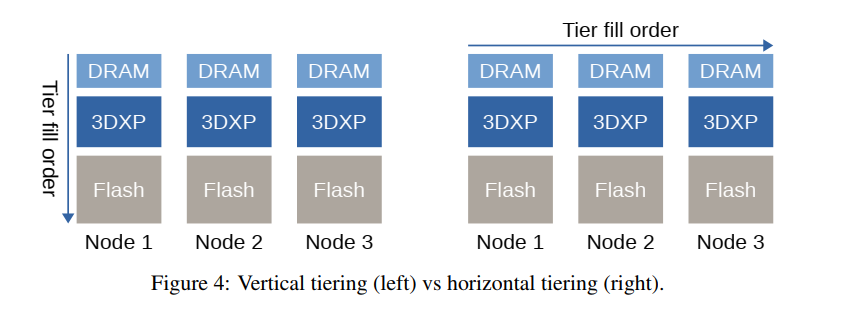
- Storage tiering:Crail提供了在文件写入期间如何分配存储块的细粒度控制。通过指定位置的远近,应用可以指定优先使用的节点以保存数据,还可以指定优先使用哪个存储层存储特定文件。在没有特殊指定要求下,Crail使用水平分层,即先填满性能较高的存储层。水平分层和垂直分层相对,垂直分层中本地资源优先远程资源。下图说明了DRAM,3DXP和flash的配置中的这两种方法。
- Crail支持3种不同的文件类型:常规数据文件、目录和multifiles。常规数据文件只允许单个writer追加和覆盖文件。Crail中的目录是包含固定字长目录记录的普通文件,这样目录枚举成了一个标准的文件读取操作。 multifile是可以并发写入的文件。
- I/O buffer:为了允许从网络接口向应用程序缓冲区放置零拷贝的数据(如RDMA中实现的那样),必须pin相应的内存并向网络接口注册。Crail暴露了方法来从可复用池中分配指定的I/O buffer——一段pinned memory且向硬件注册了,以允许绕过OS和JVM进行网络数据传输。
Crail Modules
Crail提供了两个独立的模块接入数据处理层:1)Spark模块,包含Spark特定的shuffle和broadccast操作。2)一个HDFS adaptor,允许框架和应用无缝使用Crail存储临时数据。
Evalution
A detailed evaluation of the individual components in the Crail I/O architecture (Crail store, individual modules) is beyond the scope of this paper. Instead, we demonstrate the benefits of Crail on two specific workloads, sorting and SQL, both evaluated using Spark
就是说只实现了在Spark上面进行sort和SQL操作的性能对比。
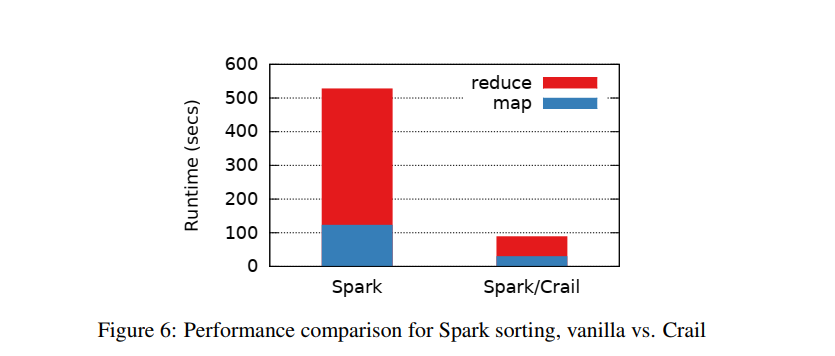
在12.8TB数据集上比较了原生Spark和使用Crail两种情况的比对,排序性能比较,Crail时间约为原生Spark1/6:
使用8台机器对总大小为256GB(2*128GB)的数据进行join操作:
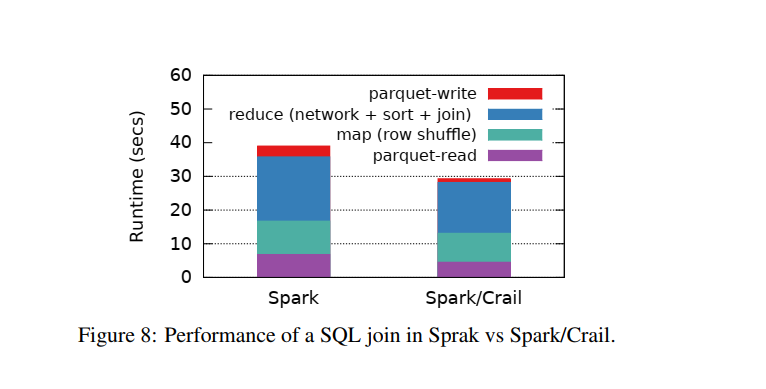
使用Spark/Crail性能提升约24.8%,在图中的4个步骤都有提升。
工作比较与贡献
最近的很多工作都致力于更好地利用快速网络或存储硬件进行数据处理。第一类是为硬件重新开发的系统:有flash优化的键/值存储,基于RDMA的键/值存储,基于RDMA的分布式内存系统,基于RDMA的分布式事务处理系统,利用RDMA的分布式join引擎,甚至是为高速网络设计的全新数据库架构。这些工作都实现了非常不错的性能。但它们往往没有集成到一个公开可用的数据处理平台和/或只针对非常特定的应用程序。相比之下,Crail是一种I/O架构,可以应用于支持泛用的应用程序和工作负载的不同开源数据处理框架。
第二类工作旨在将快速I/O硬件集成到现有系统和框架中,一些文章为了利用高速网络,将HDFS中的网络堆栈/Spark shuffle管理器重写。还有工作为了将快速网络集成到Thchyon系统中已经做出了努力。然而,所有这些工作都是在现有的基于消息的网络代码中改进基于infiniband的消息传递服务,导致性能只有微小的改进。另一方面,Crail实现了快速I/O硬件和高级数据处理操作(如shuffle、broadcast等)的紧密语义集成,从而成功地提高工作负载性能。
随着高性能网络的可用性,resource disaggregation已经成为数据处理系统的一个可行选择。一些工作证明利用高性能网络(RDMA)足以在disaggregated的数据中心维持应用性能。Crail分散的结构建立在提供快速访问远程资源的理念之上,提供了一个综合性的用来在集群中访问本地和远程存储资源的解决方案,使用细粒度的水平层控制对混合的本地和远程资源的利用。
总结
Crail I/O架构能够将快速网络和存储硬件最好地集成到分布式数据处理平台中。Crail基于分布式数据存储,作为平台特定I/O模块的快速I/O总线而存在。Crail不仅在zero-copy或异步I/O方面充分利用了现代硬件的能力,而且它还改变了在高速网络部署中使用本地和远程存储资源的方式。Crail是最近开始的一个开源项目(www.crail.io),仍然有很多机会可以做出贡献。