文献名称:A Hybrid Framework for Fast and Accurate GPU Performance Estimation through Source-Level Analysis and Trace-Based Simulation
发表于 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA)
这篇文章提出了一种框架用来预测GPU执行时间,其用于评估运行在GPU上的OpenCL内核的性能。方法:对内核执行流进行静态分析,然后通过基于循环的双向分支搜索生成执行的trace。然后动态模拟trace以生成内核的虚拟执行来获得估计时间。文章实验部分说明作者提出的方法在预测阶段开销只有几秒,能获得平均绝对百分比误差为17.04%的运行时性能。
Introduction部分:
动机:文章提到为了充分利用GPU性能,程序员需要对GPU并行原理有比较深的理解才能写出高效程序。但有的非专业用户也想把GPU用好,但是对并行不甚了解。对于此有两种解决方案,auto-tuning 和 performance estimation。
我缺乏这方面背景,所以对这两种方案解决的痛点不太了解。为啥这两种方法能解决上面提到的帮助非专业用户使用GPU的问题?
作者解释说auto-tuning由于需要使用全局/切片的design space,时间开销大,所以选择了performance estimation方法。
目前GPU性能预测模型的劣势:
- 模型的目标程序多变,需要为每个不同的应用调整参数,难以设计通用预测模型。
- 性能模型难以跟进GPU体系结构的改变。
- 细粒度模型能够给出准确性能估计,但时间开销极大,实用性差。
改进:
提出一种混合框架,基于OpenCL工作负载,评估GPU上并行程序性能。将高级内核源代码转换为LLVM IR,根据GPU的并行思想生成程序执行轨迹trace。开发了轻量级模拟器,在32个工作项(或被称为warps)的粒度下,动态地跟踪执行过程中算术和内存访问操作。
工作贡献:
- 提出了一个混合框架,结合源代码分析和基于trace的仿真来预测GPU内核的性能。目标内核的执行trace是静态生成的,然后进行模拟估计运行时性能。
- 提出了一种基于循环的双向分支搜索算法来提取内核执行trace,该trace模拟了GPU内核的warp执行流。
- 开发了一个轻量级的模拟器来模拟内核的执行,然后预测运行时的性能结果,同时考虑了IR指令管道和cache建模。该模拟器可以在几秒钟内准确预测运行在不同GPU平台上的内核的性能。
- 通过Rodinia基准测试和一个真实的应用程序,在4个英伟达gpu上展示了框架的准确性和实用性。
框架概述
框架整体结构:
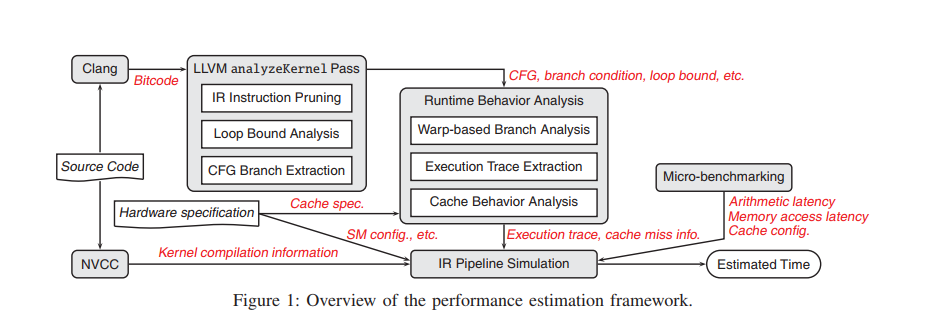
首先,源代码经过LLVM/Clang编译为二进制LLVM IR指令,同时源代码通过NVCC编译,获取详细的运行时资源使用情况在内的内核编译信息(例如share memory使用size,片上寄存器使用个数)。源代码分析模块由LLVM analyzeKernel Pass完成,二进制的LLVM代码经过LLVM analyzeKernel Pass处理,随后从内核运行时行为分析中获取执行trace。analyzeKernel pass在基本块中对IR指令剪枝,只保留对内核执行时间有贡献的算术和内存访问操作。执行流信息(如循环语句和分支)将被提取并分析,以用于后续的执行trace生成。
根据控制流图(CFG)和执行流信息,分析内核运行时行为,生成以wrap为粒度的执行轨迹trace。随后,根据cache规范和trace,获取缓存是否命中的信息。仿真模块通过构造IR指令管道并迭代地根据trace来模拟内核运行时的行为。还有一些微基准用于校准目标GPU的执行,如算术操作的延迟、内存访问操作的延迟和cache配置。这些硬件指标,以及硬件规范、内核编译信息、内核执行trace和cache缺失信息,都被提供给模拟器,以估计最终的执行时间。
源代码分析:
A. LLVM analyzeKernel pass
analyzeKernel pass收集基本block来构建目标内核的控制流图。对于每个基本块,记录IR指令来构造块内执行trace。用于生成执行trace的执行流信息是通过如下所示的三个步骤获得的。
- IR指令剪枝:假定执行时间主要由算术和访问操作组成。因此去除掉其他时间消耗无关的指令,比如LLVM内部注释指令等。
关于函数调用,因为函数调用只在某些特定时候出现,而原代码中调用某个子函数被一个详细的指令替换,因而二进制文件中并不存在子函数。只记录关于函数调用的相关信息,用以在一些时候帮助trace的生成。 - 循环边界分析: 首先使用Loopus方法来分析循环边界。当循环变量是固定常数时,Loopus可以处理。更复杂的情况时,通过对循环中的基本block执行LLVM标量演化(Scalar Evolution)分析来确定循环的边界。当Loopus和LLVM SE分析都不能给出输出时,对循环进行额外的静态分析,以进一步获取循环边界。这种静态分析的主要思想是识别循环诱导变量,并跟踪其在整个内核函数范围内的值。关于如何识别诱导变量,作者根据LLVM IR的一些形式上的特点,例如指令的形式、结构和参数等,对所有的情况做了处理,并得出循环边界的估计。
- CFG分支提取:分析每个分支路径的头和尾basic block中的phi和br指令来提取每个分支的触发条件。因为br指令与cmp指令关联,可以从中推断出分支条件。
B. Runtime Behavior Analysis
- 基于Warp分支分析:分支条件可能命中或miss,以warp的粒度进行分析分支命中情况。因为分支条件变量的值只有3种,在3种情况下基于一些假设,将分支条件命中与否作出决定。
- 执行轨迹生成:能力所限,我基本上看不懂。
- 缓存行为分析:首先使用micro-benchmarks来获取一些cache的参数,例如本地内存访问的缓存hit和miss的时延。因为OpenCL中的本地内存映射到GPU的共享内存,本地内存访问没有cache机制。如果是常量或者全局内存访问时,存储管理器首先从常量cache或者L2 cache中拉数据,如果没有就去片外DRAM拉数据。基于此,在模拟的时候需要对缓存行为建模,文章假定缓存使用LRU替换,对于memory access,在执行trace时,模拟一个常数和L2缓存的虚拟寻址空间,根据数据大小分配空间中的地址。这样在给定缓存配置下估计内存访问的缓存命中状况。
基于trace的模拟行为
A. IR 指令流水线
- 确定活动工作组的数量:每个流式多处理器(Streaming Multiprocessor)的活动工作组数量由3个条件决定:架构限制、寄存器限制和共享内存限制。这些限制条件决定的工作组数量是可以通过数学表达的,分别表示3种条件下工作组的数量,再取最小值。
- 确定算术和内存访问操作的延迟:通过OpenCL micro-benchmark测量目标GPU的算术和内存操作延时。对于一组规定的数据操作,例如整数的add、sub,浮点数的sin、cos等,分析他们在OpenCL本地内存、常量内存、全局内存访问上的延迟情况。
B. 计算trace模拟时间
给定内核执行轨迹T,算术和内存访问操作的延迟LAT,以及跟踪中的缓存丢失信息cacheMissInfo来开发一个轻量级模拟器,其使用一轮活动工作组Nawg操纵内核的虚拟执行。其预测的内核执行时间为

实验部分
使用4种商用GPU:Quadro K600,Quadro K620,GeForce GTX645,GeForce 940M。实验结果如下图:
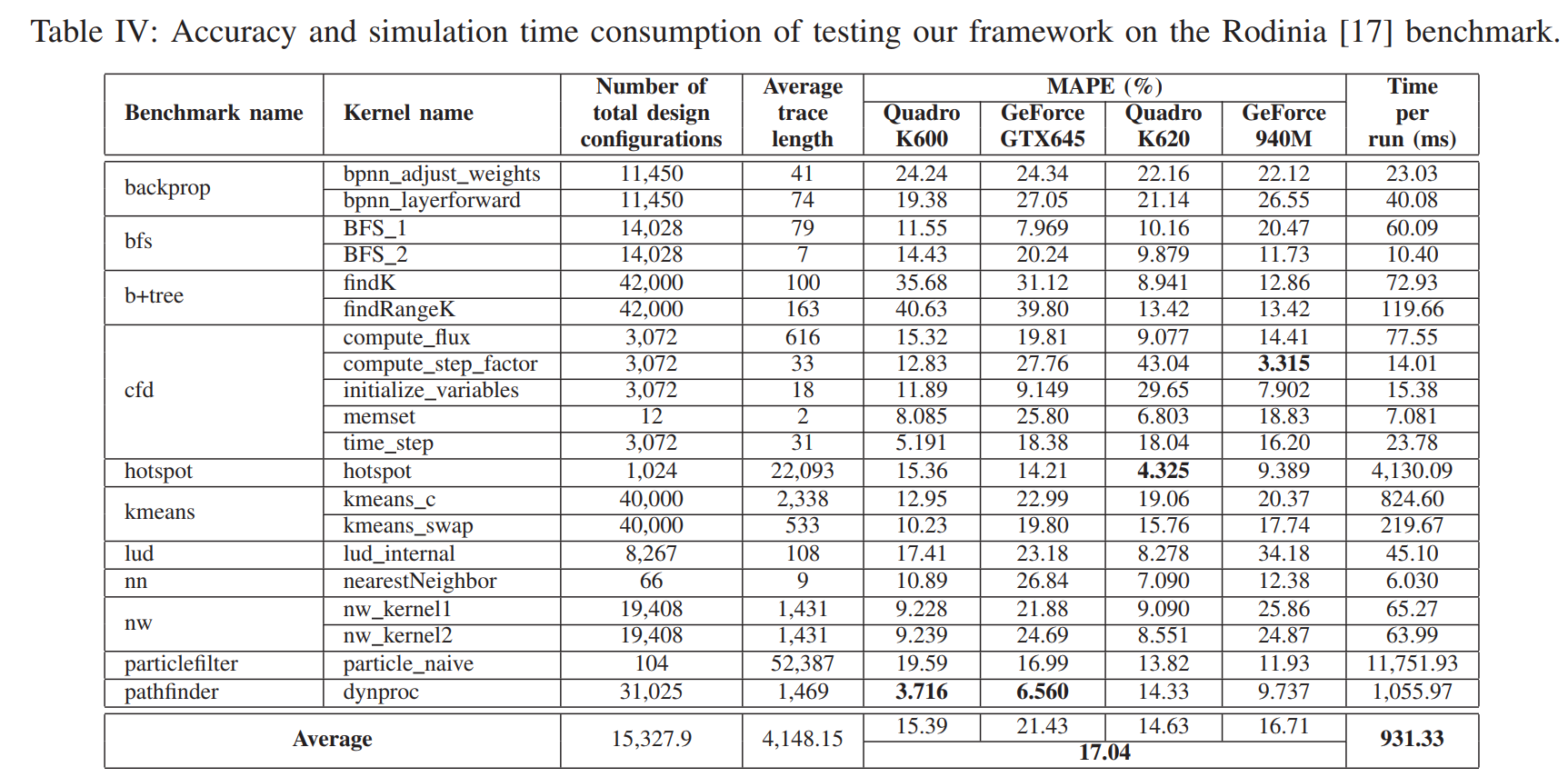
实验结果表明:4个GPU上的平均MAPE为17.04%。注意到当内核执行时间很短时(核函数nw_kernel1 and nw_kernel2),预测时间与实际时间出入较大,因为在这种情况下,内核开销占比太大,但内核开销的时间(Wrao调度,内核启动,资源调度等)是不可预测的。对于分支预测性能,例如bpnn adjust weights函数,其流程有大量依赖于线程ID的分支和嵌套分支,由于预测的路径覆盖了尽可能多的分支,会造成预测时间高估。
总的来说,该混合框架在测试集上表现良好,能够跟踪内核执行时间变化趋势。在与其他细粒度模拟器相比,论文提出的框架执行时间要少很多,在测试集上平均0.931秒内给出预测结果。