参考课程
MIT 6.824 Distributed Systems Spring 2020
https://pdos.csail.mit.edu/6.824/
1. 课程简介
MapReduce: Simplified Data Processing on Large Clusters
相关papaer中文翻译版:
MapReduce:在大型集群上简化数据处理(1):https://mp.weixin.qq.com/s/sChCf07SxhTudxFIKd8pgA
MapReduce:在大型集群上简化数据处理(2):https://mp.weixin.qq.com/s/h43tPiycGrKf9089pML2tw
MapReduce:在大型集群上简化数据处理(3):https://mp.weixin.qq.com/s/CJrvjqpPbUIrgDvSFjeZAQ
MapReduce:在大型集群上简化数据处理(4):https://mp.weixin.qq.com/s/jA4FeYBjb6fd_JyP6fzQ5g
能够单机解决的问题,不要使用分布式系统
some points:
- parallelism
- fault tolerance
- physical 物理分布
- security/isolated
some challenges:
- concurrency
- partial failure
- performance
infrastructure:
- storage
- communication
- computation
implement 实现分布式系统相关:
- RPC (Remote Procedure Call)
- Threads
- Concurrent Programming
Performance:
- Scalability 可拓展性
-- 如果我使用一台计算机解决了一些问题,然后又购买了另一台计算机来帮助我执行我的问题,如果我现在只用一半的时间就能解决问题,或者再同样的时间内我解决了两倍数量的问题,这样两台电脑每分钟干的活是一台电脑的两倍,这就是可扩展加速的一个例子 - Fault Tolerance
-- Availability 当遇到某些故障后,仍然能提供可用的服务-可用系统
-- Recoverability
--- tools: non-volatile storage 非易失性存储,更新成本高
--- Replication
Topic:
- consistency
-- strong consistency
-- weak consistency
2. RPC和多线程
线程是管理并发编程的主要工具
go语言在并发编程强于C++,因为go具有垃圾回收机制,还有好用的RPC包
线程在go里面称为Goroutine
why threads are interesting:
- I/O Concurrency 并发I/O,指的是程序可以在运行时并发地向多个服务器或者客户端等通过RPC的方式发送请求、发送信息、等待回复等
- parallelism 如果你的机器是多核CPU,那么程序将真正的并发进行
- conveniency
Thread Challenges:
- Shared Data 线程时间数据共享的问题,加锁
- Coordination 协作,即线程间如何通信协作
-- go提供的channels 和 sync.cond(),Sync.waitgroup() - Deadlock
3. GFS
论文地址: https://pdos.csail.mit.edu/6.824/papers/gfs.pdf
译文:https://www.cnblogs.com/guoyongrong/p/3700970.html
Why Big Storage Hard?
- performance -> sharding
- faults -> tolerance
- tolerance -> replication
- replication -> inconsistency
- consistency -> low performance
-- strong consistency
GFS:
- big data 大量的数据产生
- fast 快速访问,建立中间文件索引等方式
- global 通用或者全局可复用的存储系统
- sharding 把单个文件分片存储到各个服务器
- automatic recovery 自动容灾处理
- single data center 单个数据中心,没有考虑全球范围内存储副本
- internal use 仅供内部使用,不对外销售
- big sequential access 适用于大量数据连续批量处理,不适用随机访问的场景
GFS架构图(源自GFS论文 Figure 1):
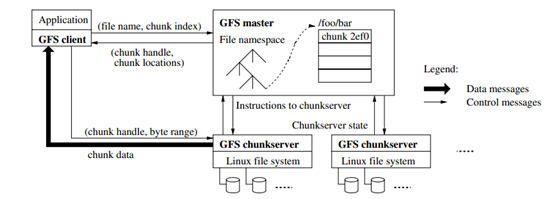
在master中,有两个值得关注的表:
- filename -> array of chunk handles(NV)
- chunk handle -> list of chunk servers(V), version(NV), primary(V) ,lease expiration(V)
V代表volatile 易失,NV代表nonvolatile 非易失
master还保存log, checkpoint,log保存在磁盘中,可以利用磁盘的B-Tree
在一个读操作里面:
客户端client把文件名filename和偏移量offset发送给master
master 发送 chunk handle 和 server list 给客户端
client 缓存 cached chunk handle and server list
client 与 chunk server 建立通信,获取数据
在一个写操作里面:
GFS把写操作都视为记录追加recode append
客户端向master询问需要追加的chunk位置在哪里,即要追加的文件最后一个chunk的位置
在没有primary的情况下:
master需要去找到包含了最新chunk副本数据的服务器集合,因为如果系统已经运行了一段时间了,但因为某些原因,chunk服务器dead,它上面保存的可能是昨天/一周前 的数据。master通过version number确定最新的副本在哪一台server或者一组server(ps:chunk server 应该知道他所持有的chunk的version ID),然后从中选择一个作为primary chunk
master 增加version ID
然后告诉primary和其他chunk 加上这个version number
master会给primiary一个lease,也就是说在过了过期时间以后这个chunk server就不再是primary了
master返回primary和secondary的信息给客户端
写操作的控制流和数据流:
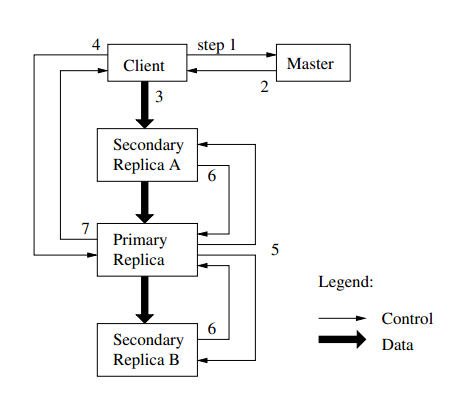
在写入数据的时候,所有的secondary和primary并不是直接追加到chunk的末尾,而是先添加数据到临时区域,在确定了数据都添加到临时区域后,priamry然后才将数据追加到chunk的末尾。secondary可能不会追加数据到它的chunk的对应偏移量offset处(可能由于发生网络故障,磁盘满了等原因),如果secondary也追加了数据到chunk,会回复yes给primary,所有的secondary都回复yes给priamry以后,priamry回复yes给客户端,否则回复no给客户端。回复no以后,客户端会重新进行append操作
(关于回复no以后的操作,实际上这里有很多可以探讨的内容)
后续待更...