Apache Ignite
中文文档:https://www.zybuluo.com/liyuj/note/230739
主页:https://ignite.apache.org/
1.1.Ignite是什么
Ignite是:
- 一个以内存为中心的数据平台
- 可持久化、强一致和高可用
- 强大的SQL、键-值存储及相关的API
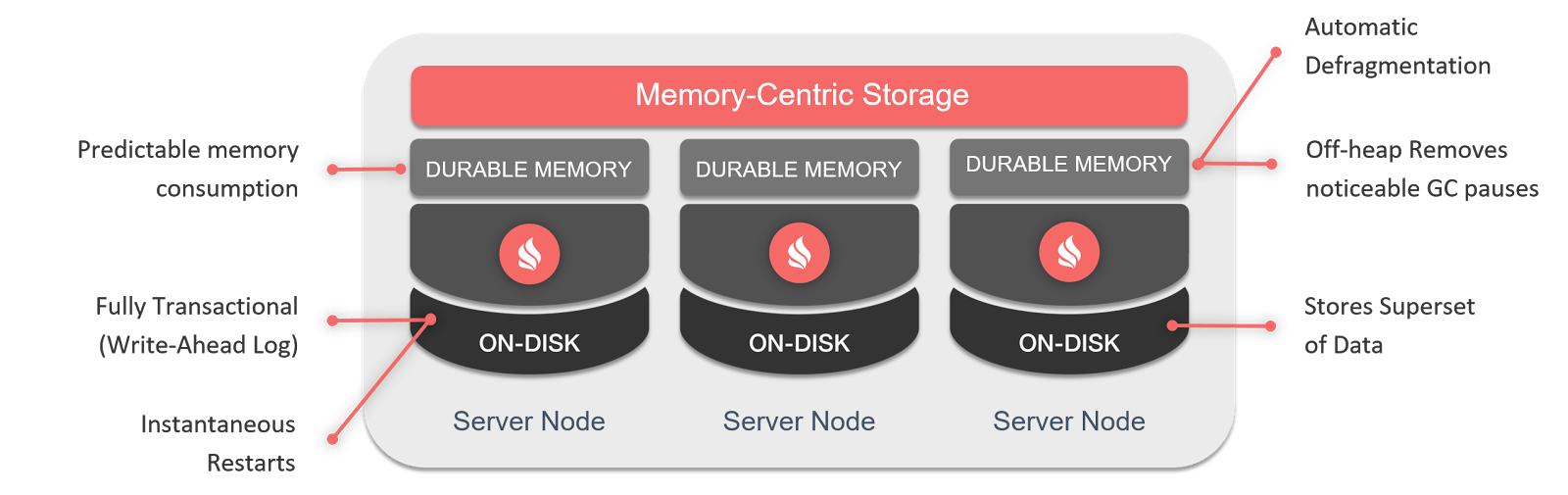
1.1.1.固化内存
Ignite的固化内存组件不仅仅将内存作为一个缓存层,还视为一个全功能的存储层。这意味着可以按需将持久化打开或者关闭。如果持久化关闭,那么Ignite就可以作为一个分布式的内存数据库或者内存数据网格,这完全取决于使用SQL和键-值API的喜好。如果持久化打开,那么Ignite就成为一个分布式的,可水平扩展的数据库,它会保证完整的数据一致性以及集群故障的可恢复能力。
1.1.2.Ignite持久化
Ignite的原生持久化是一个分布式的、支持ACID以及兼容SQL的磁盘存储,它可以作为一个可选的磁盘层与Ignite的固化内存透明地集成,然后将数据和索引存储在SSD、闪存、3D XPoint以及其他类型的非易失性存储中。
打开Ignite的持久化之后,就不需要将所有的数据和索引保存在内存中,或者在节点或者集群重启后对数据进行预热,因为固化内存和持久化紧密耦合之后,会将其视为一个二级存储层,这意味着在内存中数据和索引的一个子集如果丢失了,固化内存会从磁盘上进行获取。
1.1.3.ACID兼容
存储在Ignite中的数据,在内存和磁盘上是同时支持ACID的,使Ignite成为一个强一致的系统,Ignite可以在整个网络的多台服务器上保持事务。
1.1.4.完整的SQL支持
Ignite提供了完整的SQL、DDL和DML的支持,可以使用纯SQL而不用写代码与Ignite进行交互,这意味着只使用SQL就可以创建表和索引,以及插入、更新和查询数据。有这个完整的SQL支持,Ignite就可以作为一种分布式SQL数据库。
1.1.5.键-值
Ignite的内存数据网格组件是一个完整的事务型分布式键值存储,它可以在有几百台服务器的集群上进行水平扩展。在打开持久化时,Ignite可以存储比内存容量更大的数据,并且在整个集群重启之后仍然可用。
1.1.6.并置处理
大多数传统数据库是以客户机-服务器的模式运行的,这意味着数据必须发给客户端进行处理,这个方式需要在客户端和服务端之间进行大量的数据移动,通常来说不可扩展。而Ignite使用了另外一种方式,可以将轻量级的计算发给数据,即数据的并置计算,从结果上来说,Ignite扩展性更好,并且使数据移动最小化。
1.1.7.可扩展性和持久性
Ignite是一个弹性的、可水平扩展的分布式系统,它支持按需地添加和删除节点,Ignite还可以存储数据的多个副本,这样可以使集群从部分故障中恢复。如果打开了持久化,那么Ignite中存储的数据可以在集群的完全故障中恢复。Ignite集群重启会非常快,因为数据从磁盘上获取,瞬间就具有了可操作性。从结果上来说,数据不需要在处理之前预加载到内存中,而Ignite会缓慢地恢复内存级的性能。
1.2.Ignite定位
Ignite是不是持久化或者纯内存存储?
都是,Ignite的原生持久化可以打开,也可以关闭。这使得Ignite可以存储比可用内存容量更大的数据集。也就是说,可以只在内存中存储较少的操作性数据集,然后将不适合存储在内存中的较大数据集存储在磁盘上,即为了提高性能将内存作为一个缓存层。
Ignite是不是分布式数据库?
是,在整个集群的多个节点中,Ignite中的数据要么是分区模式的,要么是复制模式的,这给系统带来了伸缩性,增加了弹性。Ignite可以自动化地控制数据如何分区,然而,开发者也可以插入自定义的函数,以及为了提高效率将部分数据并置在一起。
Ignite是不是关系型SQL数据库?
不完整,尽管Ignite的目标是和其他的关系型SQL数据库具有类似的行为,但是在处理约束和索引方面还是有不同的。Ignite支持一级和二级索引,但是只有一级索引支持唯一性,Ignite还不支持外键约束。
从根本上来说,Ignite作为约束不支持任何会导致集群广播消息的更新以及显著降低系统性能和可伸缩性的操作。
Ignite是不是内存数据库?
是,虽然Ignite的固化内存在内存和磁盘中都工作得很好,但是磁盘持久化是可以禁用的,使Ignite作为一个纯粹的内存数据库。
Ignite是不是事务型数据库?
不完整,ACID事务是支持的,但是仅仅在键-值API级别,Ignite还支持跨分区的事务,这意味着事务可以跨越不同服务器不同分区中的键。
在SQL层,Ignite支持原子性,还不是事务型一致性,社区计划在2.2版本中实现SQL事务。
Ignite是不是键-值存储?
是,Ignite提供了键-值API,兼容于JCache (JSR-107),并且支持Java,C++和.NET。
Ignite是不是内存数据网格(IMDG)?
是,Ignite是一个全功能的数据网格,它既可以用于纯内存模式,也可以带有Ignite的原生持久化,它也可以与任何第三方数据库集成,包括RDBMS和NoSQL。
固化内存是什么?
Ignite的固化内存架构使得Ignite可以将内存计算延伸至磁盘,它基于一个页面化的堆外内存分配器,它通过写前日志(WAL)的持久化来对数据进行固化,当持久化禁用之后,固化内存就会变成一个纯粹的内存存储。
并置处理是什么?
Ignite是一个分布式系统,因此,有能力将数据和数据以及数据和计算进行并置就变得非常重要,这会避免分布式数据噪声。当执行分布式SQL关联时数据的并置就变得非常的重要。Ignite还支持将用户的逻辑(函数,lambda等)直接发到数据所在的节点然后在本地进行数据的运算。
Apache Ignite Machine Learning
文档:https://ignite.apache.org/docs/latest/machine-learning/machine-learning
Apache Ignite机器学习(ML)是一组简单,可扩展和高效的工具,它允许建立预测的机器学习模型,而无需昂贵的数据传输
痛点:
- 模型在不同系统(节点)上训练,训练后需要等待ETL或数据传输将数据(模型,参数?)转移到其他系统中。传输完成后需要在生产环境重新部署模型,耗时很长,数小时才能转移TB级数据
First, the models are trained and deployed (after the training is over) in different systems. The data scientists have to wait for ETL or some other data transfer process to move the data into a system like Apache Mahout or Apache Spark for a training purpose. Then they have to wait while this process completes and redeploy the models in a production environment. The whole process can take hours moving terabytes of data from one system to another. Moreover, the training part usually happens over the old data set.
- ML、DL算法处理的数据集不在单一服务器上,数据集往往是一个增长的数据集。需要科学家提出复杂的解决方案,或者转向分布式计算平台(Apache Spark and TensorFlow)。这些平台解决了部分模型训练的问题,而对未来在生产环境部署产生负担。
The second factor is related to scalability. ML and DL algorithms that have to process data sets which no longer fit within a single server unit are constantly growing. This urges the data scientist to come up with sophisticated solutions or turn to distributed computing platforms such as Apache Spark and TensorFlow. However, those platforms mostly solve only a part of the puzzle which is the model training, making it a burden of the developers to decide how do deploy the models in production later.
特性:
-
Zero ETL and Massive Scalability 零ETL和大规模可拓展、
允许用户直接对集群中内存和磁盘上存储的数据进行训练、推理
提供DL、ML算法,对Ignite的并置分布式处理进行优化,针对增长数据集或大数据集,不需要在不同的存储中移动数据,消除ETL(Extract Transform Load) -
Fault Tolerance and Continuous Learning 容错 持续学习
所有的恢复过程对用户都是透明的,学习过程不会被中断,我们会在类似所有节点正常工作的时间内得到结果。
......未完