文献:Alluxio: A Virtual Distributed File System
该项目网址:https://www.alluxio.io/
本论文为伯克利一博士的毕业论文,非一般会议、期刊论文。并且是github上的开源项目。
概念
Alluxio引入了一种新的抽象:虚拟分布式文件系统(VDFS)。VDFS位于计算层和持久层之间。它有两组API,南向API (SAPIs)和北向API(NAPIs)见下图。SAPIS使VDFS连接到不同的存储系统,而NAPIs为应用程序提供不同的API,应用能够通过VDFS与数据进行交互且不需要任何代码上的修改,并能在不同存储系统之间有效地共享数据。VDFS可以抽象所有这些持久存储系统公开的各种API,向上提供统一接口,将NAPIs暴露给VDFS之上的应用程序。Alluxio将市面上各种流行框架集成起来,它位于常用计算框架如Apache Spark、Presto、Tensorflow、Apache MapReduce和常用持久层如Amazon S3、Apache HDFS、EMCECS、Ceph之间。
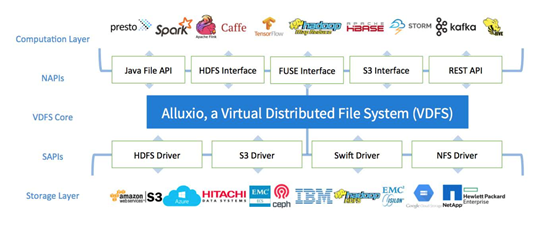
图1:VDFS,Alluxio as an example(from Alluxio paper)
Alluxio的内部设计结构是一个以内存为中心的架构,它允许应用以内存I/O速度访问Alluxio(通过Alluxio API等方式),同时,因为Alluxio位于不同的计算层和存储层之间,它能够透明地向应用层提供cache,同时支持数据共享。
关于Alluxio主从结构
Alluxio遵循主从结构(master-worker),主节点(master nodes)负责管理Alluxio系统元数据,并且负责处理元数据请求和集群注册。从节点(worker nodes)管理每一个部署本地存储媒介,负责处理数据请求,并且从Alluxio存储或者其他数据仓库中传输数据给客户端。
主节点通常只有一个节点(也可以有一批节点),负责管理Alluxio文件系统和集群的状态。除了管理元数据,master也存在一个工作流管理器(workflow manager),负责跟踪沿袭信息,计算检查点顺序(checkpoint order),和集群资源管理器交互以为重计算任务分配资源。有多个主节点时,同一时间只有一个主节点被激活用来处理请求,其他master node只参与保持日志为最新版本,以便当激活节点挂掉时,直接进行热故障恢复(stanby服务器启动,读取log,接管服务)。所有主节点的关系通过Apache Zookeeper组件进行注册管理。
Alluxio主节点master管理worker从节点的关系,为每一个worker注册一个独特ID,跟踪分配了ID的worker并且保持其数据在每一个其他worker中都可用。通常Alluxio期望一个worker的ID只和一个master相关联。Master将文件划分为块,以块(block)为最小单位记录组成文件的块的元数据,块大小在数十到数百MB。每一个块都有其独特ID,并且可以在0、1或无数个worker中都存储一份。
Alluxio master允许客户端和worker随意的加入和离开集群。客户与master通信以便在逻辑上更新元数据。这些请求都是独立、无状态的,这样master可以并发的处理客户端上万请求。而worker通过周期性的心跳和master通信,心跳信息开销很小,这样Alluxio集群可以扩展到数千节点,也不必担心master负载问题。
Alluxio master通过维护一份日志事件来进行容错,日志通过分布式方式存储,避免单节点故障导致日志失效。
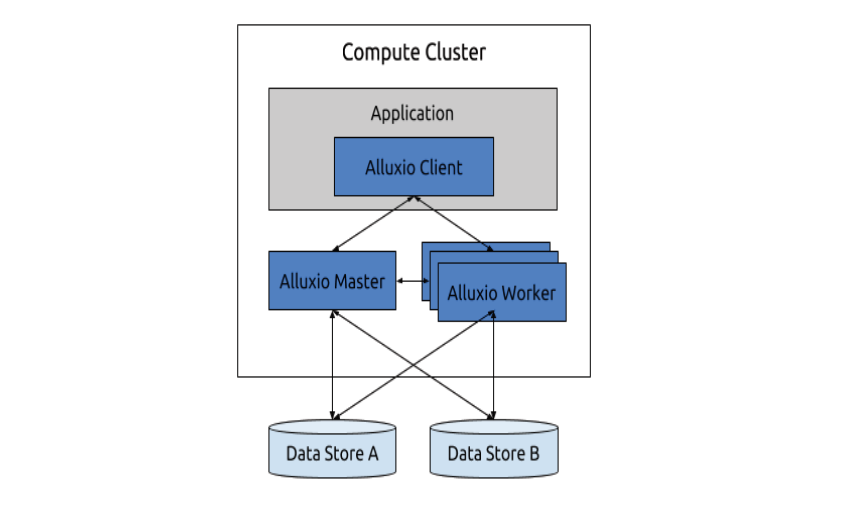
Alluxio worker在Alluxio的集群的每一个服务器上都有部署进程,负责管理本地存储媒介,对外提供数据访问服务。Worker是一个轻量级的进程,其不依赖于持久层,并且在设计上容忍性强,能够容忍(tolerate)worker和本地存储的完全丢失。
将worker进程和应用部署在同一个节点上,这提供了数据局部性,这样可以极大的提高性能。应用可以以内存访问速度访问节点上的数据,当需要大量的I/O负载时,通过这种方式有效地减少了网络传输,提高应用速度。同时,worker也可以部署在专用节点上。这样的优势在于可以隔离worker,比如应用只是短暂的加入集群,或者应用节点还没提交到集群。一个这样的例子是:存在一组工作节点,他们为不同的计算集群提供服务,而计算集群不必担心自己的资源因为其他计算集群的工作负载而被Alluxio抢占。
Alluxio worker主要功能就是为客户端访问数据提供支持,这有两种方式实现:1)直接从Alluxio本地存储获取数据;2)从底层的数据仓库/存储中获取数据,例如HDFS,Amazon S3。从底层获取的数据会被缓存到Alluxio本地存储中,同时会使用LRU、LFU策略逐出缓存。
关于Alluxio沿袭机制
一个典型架构如图2:由ZooKeeper负责注册各个Master的状态,Tachyon Master负责管理各个worker的状态,worker本地运行worker进程,通过Ramdisk存储内存数据。
现存的主流分布式存储系统都通过向cache中存放数据获取较高的IO性能,这样对文件读性能有很大提高(如内存计算框架Spark使用cache存储数据,提高了单个任务执行效率),但对文件写(例如Spark的多个任务共享数据)几乎没有帮助。因为很多系统为了保证容错,都使用了多副本拷贝方法,在写入时显然必须通过网络传输数据到多节点上同时写入,性能较差。Alluxio为了提高文件写性能,引入了沿袭(Lineage)机制,同时确保容错机制。当Alluxio丢失数据时,其通过重新执行任务/操作来重新创建结果,这样数据可以不用在多个节点备份来确保容错。一个注意的点:Alluxio的思想是通过沿袭机制,避免数据复制/备份,来提高写性能。但是多份数据可以明显提高读性能,Alluxio使用一种客户端缓存技术(client-side caching technique)来提高热点数据的读性能:当一个文件在本地机器上无法访问/不可用时,文件将从远端机器拉取并缓存到本地的Alluxio中,并短暂增加它的复制因子。
实际上,沿袭机制在Spark、Nectar、BAD-FS中都有使用,但Alluxio作为一个分布式存储系统,仍然遇到了一些不同的困难。
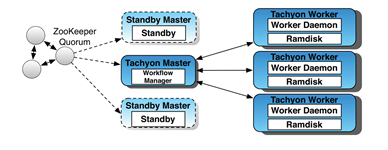
图2:Alluxio,formerly Tachyon,Architecture(from Alluxio paper)
其一是难以限制重计算开销,对于单个计算框架,例如Spark,MapReduce,其重计算时间取决于任务执行时间。但是Alluxio运行具有不确定性,意味着重计算时间可以是无限长的。对于长时间工作负载任务,Spark Streaming用周期性的建立检查点(checkpointing)的方法来克服这个困难。但是Alluxio中存储的数据用于哪个计算框架的任务是不可知的,任务的执行特征也是会变化的。于是,如果数据写入速度大于可用磁盘带宽,但使用了相同间隔的检查时间(checkpoint interval),那么恢复时间也是不可确定的。Alluxio根据沿袭图的结构来确定要进行checkpoint的建立,但这仍然可能导致不可知的恢复时间。
其二是如何为重计算任务分配资源。一个优先级较高的任务,Alluxio需要确保该任务获得合适的资源,同时也不能影响当前运行的其他任务的性能。Alluxio通过在后台异步、持续的进行checkpoint的方式,限制了数据恢复的开销上限。为了确定何时选择文件来进行检查,Alluxio提出了novel算法,称为Edge算法,其提供了一个恢复任务开销的上界,而与工作负载的访问模式无关。Alluxio提供两种集群资源分配模式:严格优先级模式和权重公平模式。严格优先级模式下,如果一个低优先级的任务所需数据丢失,那么该数据恢复任务所用资源会将其对高优先级的任务的影响降至最低。
Lineage开销
lineage信息中占用存储空间最多的是任务的二进制文件,但是根据Microsoft data数据,一个典型数据中心平均每天运行1000个任务,一年下来存储未压缩二进制文件使用存储约1TB空间。这样的花销是可接受的,即使对于小的数据中心也是可以接受的。另外,Alluxio可以对沿袭信息进行垃圾回收,当任务的输出文件checkpoint完成后,Alluxio可以删除掉沿袭记录。这可以有效减少沿袭信息占用的存储空间。
数据排除(data eviction),置换策略
Alluxio工作在内存级速率上,当内存满了,如何置换?
Alluxio根据(Interactive analytical processing in big
data systems: A cross-industry study of MapReduce workloads)数据密集型应用的访问频率和访问时间局部性,使用LRU(Least Recently Used)方法在内存中剔除数据。同时因为LRU并不是适用于所有场景的,Alluxio也支持插入其他逻辑剔除数据。
关于检查点技术(checkpointing)
根据某些特性/原因,Alluxio使用Edge 算法来进行checkpoint,Edge算法建立在三个想法之上:其一,Edge检查lineage graph的边缘(叶子),并由此得名。其二,结合优先级,对优先级高的文件checkpoting优先级也高(相比较优先级低的文件)。其三,Edge算法只缓存那些能够放入内存的数据集。
checkpointing leaves
Edge算法使用DAG对文件关系进行建模,图的顶点为文件,如果文件B由文件A生成,那么有一条边由A指向B。Edge算法checkpoint DAG中叶子节点的数据,checkpoint最新的数据。
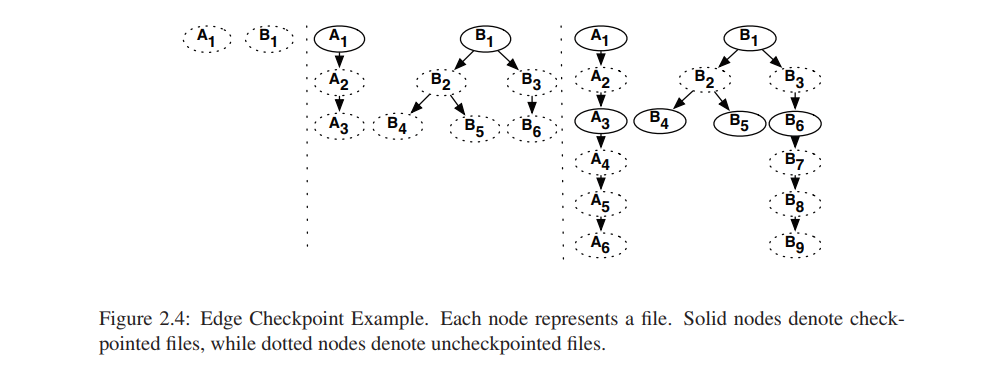
图2.4为一个例子,一开始有两个任务产生了A1和B1,checkpoint它们。然后任务生成了第二部分文件,A3、B4、B5、B6成为叶子节点,checkpoint它们。然后生成第三部分文件,A6、B9成为叶子节点,checkpoint它们。
优势:考虑A1->A6这个任务,如果A6的checkpoint失败,那么重计算任务只需要生成A4->A6这几个文件,不用进行一个长链的A1->A6的重计算。
checkpointing hot files热点文件
Alluxio使用文件被访问的次数来为其分配特权优先级,类似于LFU(Least Frequently Used)策略,来保证访问频次多的文件被优先checkpoint。内在逻辑是访问频次高的,用以其他任务生成文件的概率也高,有利于故障恢复过程。
处理大型数据集
工作集呈现Zipf分布,可以将全部(非常巨大的数据集除外)数据存到内存中。例如,facebook的MapReduce任务的输入集呈现heavy-tailed分布,另外,96%的活动任务同时将他们的数据写入到集群的内存中。Alluxio master因此需要配置为同步地将超过临界值的数据集写入磁盘的模式。此外,集群中对文件的请求是爆炸性(时间上,极短时间内请求了大量数据)。在爆炸性增长时,DAG图延伸得很快,checkpoint的叶子节点相隔得非常远。在增长减缓时,Edge算法开始checkpointing那些剩余的非叶子节点的文件。因此,大部分时间大部分内存中的文件都是被checkpoint过了的,于是可以根据算法将其剔除(上面提到过数据置换策略)。如果Alluxio中被填充了大量未被checkpoint的数据,那么Alluxio将同步地将其checkpoint,以避免重计算过长的链路。总之,存储所有(非常巨大的数据集除外)的数据集在内存中,将使得大部分数据都有足够时间来checkpoint。
关于资源分配
大多数情况下,一个数据中心、集群都是有空闲资源可以分配的,然而也需要考虑集群满载的情况。Alluxio遵循三个目标来设计资源分配方案:
- 优先级兼容:如果计算任务具有高低优先级,那么重计算任务也具有高低优先级。一个低优先级的任务需要的文件失效,那么该文件的恢复任务的优先级也低;如果优先级高则反之。
- 资源共享:如果集群中没有重计算任务,那么所有的集群资源都应该被用于普通的工作。
- 避免级联重计算:就是避免循环计算,当一个失败发生时,往往涉及到多个文件的恢复,如果不考虑这些数据的相互依赖关系,那么就很有可能发生循环依赖的文件发起多次重计算任务的情况。
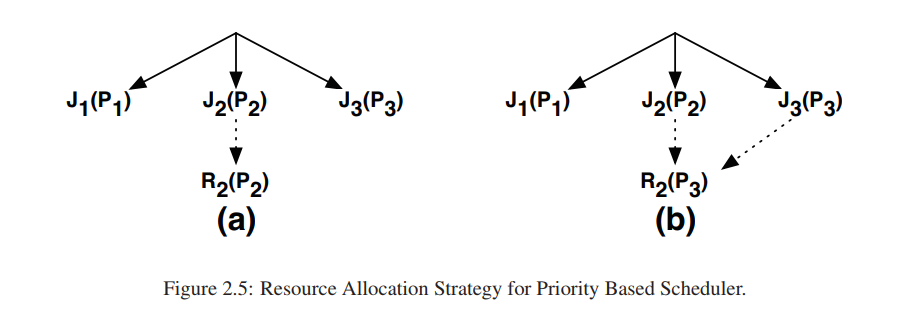
对于优先级兼容的情况,重计算任务使用特权继承的方式来执行。一开始重计算任务的优先级都非常低,但这可能造成计算任务阻塞,为了避免计算任务阻塞,重计算任务R2的优先级也继承任务J2的优先级为P2(P1 < P2 < P3),如果文件F2最后被J3任务访问了,那么R2的优先级赋值为P3。
对于资源共享机制,用一个例子来描述这个过程:
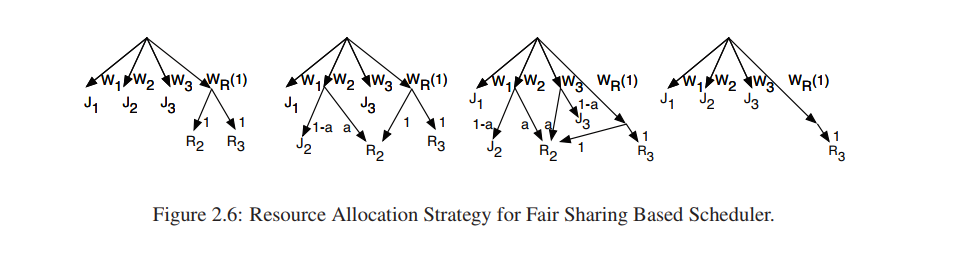
一开始J1、J2、J3各自有W1、W2、W3的份额,WR(最小为1)是Alluxio默认权重份额,是所有的重计算任务的份额。当进行故障恢复时,所有重计算任务都各自被分配WR的份额。当一个任务J2需要重计算的文件F2时,J2把自己的份额为a的部分共享出来(a为一固定值,例如20%),于是W2中有a被分配给R2重计算,有(1-a)分配个J2的任务。如果J3也需要F2文件,那么J3也分配a份额出来给重计算任务R2,当F2重计算完成后,J2和J3的份额恢复到原来的W2、W3。
好处:这样的优势在于既实现了优先级兼容,又实现了资源共享,如果正常计算任务没有请求一个失效文件,那么失效文件的重计算任务对资源的开销是有一个上界的,在这里就是WR/(W1+W2+W3+WR);当存在计算任务需要失效文件了,那么计算任务分配了自己的资源给失效文件恢复任务,这也不影响其他正常运行的任务继续执行。
对于避免循环构建重计算任务:根据已有的DAG,从需要的文件开始使用DFS算法,找到第一个在内存中存在的节点,从这个节点开始重计算任务。
不足之处
Random Access Abstractions 随机访问抽象
数据密集型应用运行任务的输出文件放到存储系统中:比如Alluxio。通常,这些文件都被重新使用,例如放入DBMS中,这样允许用户级别的应用通过接口来访问、使用这些数据。例如一个Web应用的数据可能被多次访问。因此,Alluxio需要提供更高层级的只读随机访问抽象(例如 key/value 接口)来让那些输出文件直接可以在任务完成以后就允许被访问了。
Mutable data 可变数据
目前Alluxio存储的数据写入后就成为了immutable data。因为lineage机制的原因,要使data为细粒度的随机访问进行更新是一个不小的挑战。有几个方向可以考虑:确定性更新(exploiting deterministic updates)和批更新(batch updates)。
Hierarchical storage 分层存储
尽管内存容量每年都在爆炸性增长,但内存与其他存储相比仍然相当昂贵。Alluxio需要利用其他形式的存储,例如NVRAM、SSD等。正如NVM正在以更低的花销和相似的性能替代DRAM,在未来,Alluxio也在向支持层次化存储的方向努力。
checkpoint算法优化
目前Alluxio提出的Edge算法,提供了重计算任务时间开销的上界,同时对热点文件checkpointing优先级高,还避免了临时文件checkpoint。但是如果从其他指标来衡量checkpoint技术(比如checkpoint开销、单个文件恢复开销、全部文件恢复开销等),还会有不一样的算法逻辑。checkpoint的逻辑仍然需要在未来做出调整。
系统诊断
调试一个分布式系统是非常复杂的一件事,因为系统中多种多样的组件和各种因素都会影响单个客户的请求,issue也难以复现和解释。经验说明Alluxio提供更简单的debug分析可以提供非常巨大的价值。Alluxio正在改善logging系统,CLI工具,以及web接口来使得系统诊断更加容易。
数据压缩/数据加密
Alluxio可以对内存中的数据进行压缩,以使得宝贵的内存资源得到更多利用。同时Alluxio存储数据到下层存储中时,可以对数据进行加密。
非局部性数据访问
当任务访问数据不在本地时,不满足locality特性,仍然需要通过网络访问数据,这样数据访问bottleneck又到了网络上。
master元数据存放
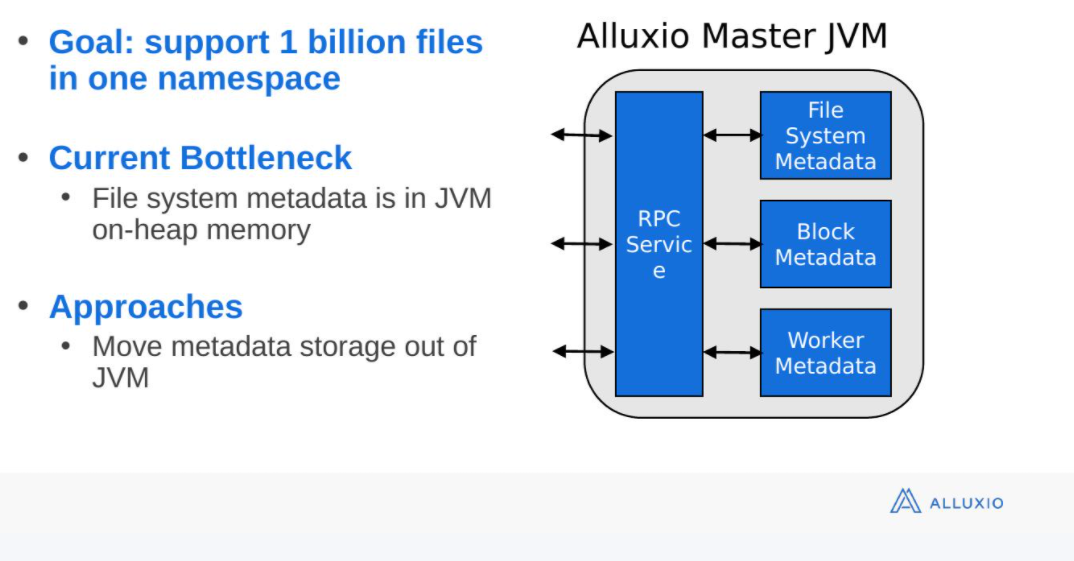
master元数据存放在JVM的堆内内存中,限制了元数据的增长。由于JVM GC机制,过大的堆会造成GC停顿时间过长,影响效率。
——————
其他资料:
https://www.slidestalk.com/Alluxio/Alluxio_2_0_Overview